СОГАЗ: клиент — это не человек – отзыв о страховой компании СОГАЗ от «ИгорьSMOL»
05.02.2020 обратился на сайт страховой копании СОГАЗ для продления полиса ОСАГО. В личный кабинет сайт не позволил войти в течении полутора часа. В этот же день обратился в поддержку, на сайте компании указав причину. Ответ пришел на телефон в виде СМС только через сутки!!!06.02.2020 в личном кабинете данного сайта заполнив требующие данные стал пытаться отправлять данные через сайт. Не все так просто, на сайте надо в вести секретные символы… Секретные символы, не читаемые человеческим глазом, сайт принимает с 10 – 15 раза отвечая, что “неверные символы”. Умудрившись все таки впихнуть чудо символы в коробку, через 5 минут приходит ответ, «ответ от РСА не получен» и так пять — восемь раз . Сначала шаманские действия с секретным кодом, потом отказ.
Через некое время, около двадцати минут после последней подачи, приходит ответ, что данные прикрепленные не точные, водитель, тот на кого ранее оформлялась страховка нет в РСА, отредактируйте, пришлите снова.
Продолжаем снова подгружать те документы, которые были загружены ранее, дополнять старую информацию, начинаем снова танцы с бубнами перед секретными символами и снова отправляем, теперь ответ придет через 15 -20 минут. И снова ответ, «ответ от РСА не получен». И так далее и все по той же схеме.
В результате танца с бубнами через пять часов приходит финишное заявление: “Уважаемый клиент! В соответствии с Указанием Банка России № 4190-У процедура заключения договора ОСАГО не может быть продолжена в связи с тем, что электронные копии документов, необходимые для заключения договора ОСАГО, предоставленные Вами по истечению 3 часов с момента направления Вам уведомления о непрохождении проверки в АИС ОСАГО и необходимости предоставить электронные копии документов.
Не уж то страховым компания все по одному месту или у нас совсем не работают, без действуют контролирующих органы Банка РФ, ФАС, РСА, Роспотребнадзор, Прокуратуры? Попытка еще раз на следующий день, не к чему не привела, все то же самое. Обращение в тех поддержку тоже безрезультатно, прошло четверо суток, ответа нет!
Как проверить полис ОСАГО на подлинность в базе РСА?
Добрый день, уважаемый читатель.
В этой статье речь пойдет о том, как проверить полис ОСАГО на подлинность через базу российского союза автостраховщиков.
Дело в том, что в последнее время на рынке ОСАГО появилось большое количество мошенников. Обманывают страховые компании разными способами. Некоторые пытаются навязать дополнительные услуги под видом обязательных. Другие продают поддельные полисы ОСАГО, по которым невозможно получить выплаты.
В связи с этим появилась информация о том, что российский союз автостраховщиков заставит всех водителей заменить страховые полисы с 1 июля 2016 года. Однако данная информация нормативными документами не подтверждена, поэтому воспринимать ее всерьез преждевременно.
Однако данная информация нормативными документами не подтверждена, поэтому воспринимать ее всерьез преждевременно.
Рассмотрим, как проверить подлинность страхового полиса.
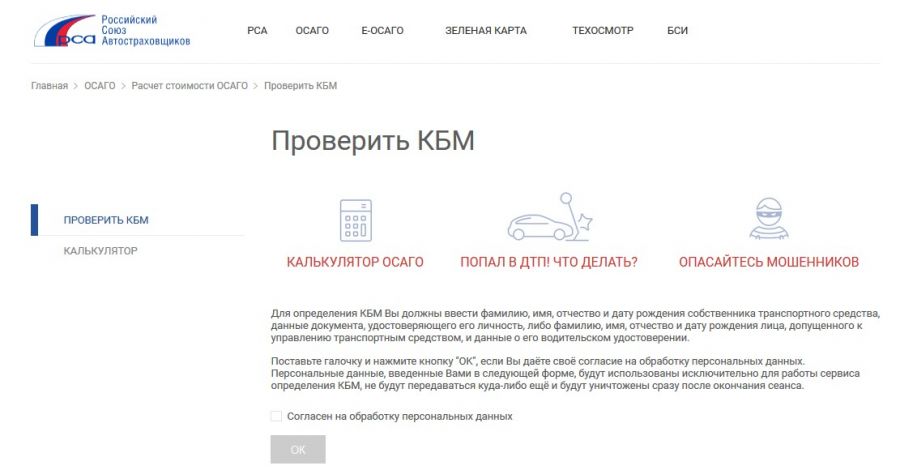
Проверка подлинности полиса ОСАГО
Проверка подлинности ОСАГО на сайте РСА — достаточно простая процедура. Для проверки воспользуйтесь следующей формой:
1. Возьмите в руки Ваш страховой полис. Обратите внимание на правый верхний угол, где указаны его серия и номер.
2. Выберите серию полиса в ниспадающем списке.
3. Введите номер полиса в соответствующее поле.
4. Введите проверочный код и нажмите на кнопку «Поиск».
После этого возможны различные результаты.
Подлинный полис ОСАГО
Если все данные в таблице соответсвуют данным Вашего полиса, то все в порядке, он является подлинным. Беспокоиться Вам не о чем.
Кроме того, статус полиса должен иметь значение «Находится у страхователя».
Недействительный полис ОСАГО
Возможны несколько вариантов недействительного полиса:
1. Полис не найден.
Полис не найден.
В данном случае полис является поддельным.
2. Полис не выдавался.
Это сообщение означает, что у Вас на руках находится копия настоящего полиса. Настоящий же полис до сих пор у страховой компании.
3. Полис утратил силу.
В данном случае полис был выдан, однако впоследствии был аннулирвоан.
4. Полис просрочен.
Указанный полис действовал до ноября 2015 года и в настоящее время является недействительным.
Внимание! Если Вы получили одно из четырех указанных сообщений, то в первую очередь купите новый полис ОСАГО. Это позволит Вам избежать штрафа за отсутствие страховки. Только после этого нужно обратиться в страховую компанию, выдавшую поддельный полис, за разъяснениями и возвратом денег.
Обратите внимание, при использовании поддельного полиса ОСАГО виновник ДТП будет платить за ремонт чужого автомобиля из собственного кармана.
В заключение хочу отметить, что проверка полиса ОСАГО по базе РСА занимает всего несколько минут. Поэтому рекомендую проверить имеющийся у Вас полис и в случае необходимости своевременно принять меры.
Поэтому рекомендую проверить имеющийся у Вас полис и в случае необходимости своевременно принять меры.
Удачи на дорогах!
Нет скидки по осаго почему
Как вернуть или восстановить скидку КБМ на ОСАГО I ОСАГОиКАСКО.НЕТ ™
Опубликовано в СтатьиСтрахование автомобиля по ОСАГО – ежегодная процедура у всех автолюбителей. И каждый автолюбитель знает, что ему положено по российскому законодательству об ОСАГО, скидка 5% за каждый год безаварийной езды. Также напоминаем максимальная скидка составляет 50% от стоимости страхового полиса.
В этом году были повышены тарифы на ОСАГО начиная с 9 января 2019 года и каждый страхователь не прочь бы сэкономить на покупке страховки, но случается ситуация, когда вы приходите покупать полис ОСАГО к страховщику и вам сообщают, что скидок на ваш полис нет. Что делать в такой ситуации давайте разбираться.
Что нужно знать о скидке КБМ на ОСАГО
- КБМ – страховой термин и аббревиатура и расшифровывается как “коэффициент бонус-малус”
- Бонус – в переводе “хороший” или “скидка”
- Малус – в переводе “плохой” или “увеличение стоимости”
За что дается скидка и как она применяется
Дается скидка за безаварийную езду на автомобиле и задумана как социальное стимулирование водителей за безопасное движение и соблюдение правил дорожного движения.
При страховании скидка заносится в единую специальную базу РСА и закрепляется за водительским удостоверением каждого водителя допущенного к управлению автомобиля вписанного в страховой полис.
При страховании полиса ОСАГО с допуском к управлению автомобиля без ограничения водителей, скидка закрепляется за собственником транспортного средства. При продаже автомобиля или смене собственника скидка обнуляется всегда.
Как вернуть или восстановить скидку на ОСАГО
Контроль и за работу страховых компаний отвечает надзорная организация РСА – Российский Союз Автостраховщиков.
Для решении данной проблемы есть несколько вариантов:
1. Попытаться разрешить данную ситуацию путем переговоров со страховой компанией, если вы страхуетесь там не первый год.
2. Написать жалобное обращение в РСА по КБМ.
При подачи жалобы на некорректное применение скидки следует обязательно указать:
- Ф.И.О полностью
- дату рождения
- серию и номер водительских прав с приложением обязательно их копии или скана
- серию и номер Паспорта РФ с приложением обязательно копии или скана (для тех, кто страховался без ограничения к допуску управления автомобилем)
Отправить жалобу с прикрепленными копии документов по электронной почте [email protected]
На ответ по вашей жалобе отводится 30 рабочих дней, и если вы забудете прикрепить копии документов, то жалоба не будет даже рассматриваться.
3. Новый способ вернуть скидку – это обратиться в наш отдел по страхованию по телефону +7 (499) 399-34-53 , предоставить документы (паспорт и водительское удостоверение) и мы восстановим вашу льготу КБМ по ОСАГО через базу РСА в течении от 1 суток до 10 дней. (услуга платная)
Вот и всё, с чем хотели мы с вами поделиться. Приятного вам страхования!
Другие статьи:
Пропала скидка по ОСАГО — обнулился КБМ, причины и советы
Многие водители, в очередной раз обращаясь к страховщику за оформлением страхового полиса ОСАГО, рассчитывают, что могут получить скидку. КБМ (Коэффициент бонус-малус) может быть начислен за стаж вождения или за отсутствие ДТП по вине водителя в предыдущий страховой период. Но, может случиться, что обратившись в страховую компанию, агент может не найти КБМ.
Почему пропала скидка по ОСАГО
Существует несколько причин, почему коэффициент бонус-малус не был обнаружен.
- Внесение водителя в несколько полисов одновременно.

- Ошибка страховой компании. Если страховщик не внес данные в базу РСА, или же при внесении данных была допущена какая-либо ошибка, КБМ водителю на засчитается.
- Мошеннические действия. Сегодня все чаще встречается информация о нелегальных мошеннических страховых компаниях, которые выдают недействительные страховые полисы ОСАГО. Как правило, такие страховщики ссылаются на то, что отсутствует связь с Российским союзом автостраховщиков, утверждая, что информацию сразу передать невозможно, и что данные будут внесены чуть позже.
- Намеренный обман со стороны страховщика. Некоторые страховые агенты могут намеренно не передавать данные в РСА, ссылаясь на то же отсутствие связи. Делается это с целью того, что при отсутствии КБМ клиент заплатит страховщику значительно больше, что, конечно, выгоднее для страховой компании.
- Неправильные действия при расчете скидки по ОСАГО. Иногда КБМ учитывается, но его значение намного меньше, чем ожидал страхователь.

Перед тем, как предъявлять претензии к страховой компании, убедитесь, что вы правильно рассчитали КБМ.
КБМ после ДТП
Если дорожно-транспортное происшествие произошло по вашей вине, то, конечно, ваша скидка будет значительно меньше. Точное снижение КБМ вы сможете узнать у специалистов своей страховой компании. Если же ДТП было совершено по вине другого участника дорожного движения, вам необходимо будет предоставить оказательству страховому агенту о своей невиновности. В качестве доказательств можно предоставить копию протокола или же справку от дорожно-транспортной полиции. При наличии достаточных доказательств об отсутствии вашей вины в ДТП, страховщик обязан вернуть прежний класс КБМ и сохранить скидку по ОСАГО.
Причины обнуления скидок по ОСАГО и способы их восстановления
Каждый собственник автомобиля, проверяя состояние своего действующего страхового полиса ОСАГО, может обнаружить, что обнулились (исчезли) все скидки по страховке, которые ранее предоставлялись страховой компании. В этой ситуации у владельца машины возникнет несколько вопросов: «Почему потерялись скидки на ОСАГО?» и «Что делать, чтобы скидку по ОСАГО вернуть?».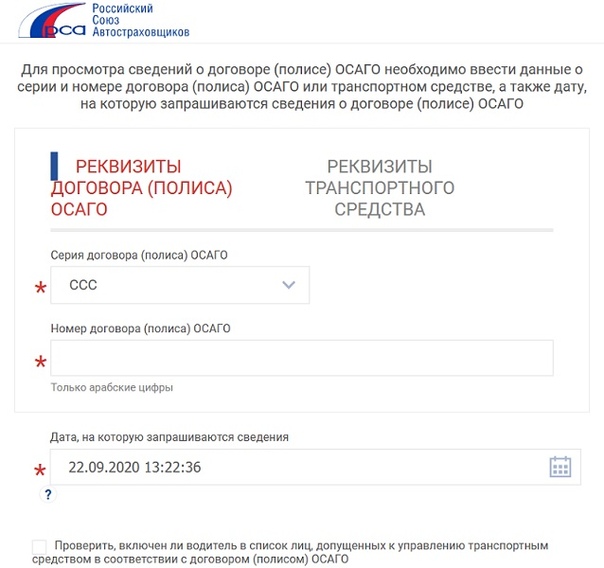
Причины, влияющие на потерю скидок
Почему потерялись скидки по ОСАГО? Это могло произойти по нескольким причинам:
- водитель автомобиля не вписан в полис ОСАГО на протяжении периода, равного или большего одного года;
- страховщик по какой-либо причине не внес информацию о водителе или собственнике автомобиля в базу РСА;
- куплена поддельная страховка;
- намеренный обман водителя со стороны представителя страховой компании;
- неверное мнение о наличии скидок;
- оформлен страховой договор без ограничений по водителям;
- потерялся КБМ после аварии.
Водитель не вписан ни в один действующий страховой полис на протяжении 12 месяцев
Возможна ситуация, когда окажется, что водитель не вписан в действующий полис ОСАГО на протяжении последних 12 месяцев. Это приведет к тому, что все имеющиеся ранее скидки по страховке аннулируются в автоматическом режиме.
Информация о водителе не внесена в базу РСА
Сведения о водителе могут быть не внесены в базу РСА по нескольким причинам:
- человеческий фактор – забывчивость или невнимательность сотрудника страховой компании в момент занесения в РСА сведений о страхователе;
- недействительный полис – если страховка не подлинная, то и информация о страхователе не будет внесена в базу РСА.

Куплена поддельная страховка
Поддельная страховка является недействительным документом. Поэтому наличие такого документа на протяжении одного года приравнивается к отсутствию действующего полиса ОСАГО в течение 12 месяцев.
В РФ зафиксировано много случаев продажи страховой компанией поддельных полисов ОСАГО. Наиболее часто в такой деятельности замечена компания «Росгосстрах».
Обман водителя
Страховой агент может неумышленно либо целенаправленно утаить от водителя наличие имеющихся скидок по ОСАГО. Эти действия могут быть совершены с целью получения большей прибыли, так как клиенту потребуется заплатить большую сумму при оформлении страховки.
Неверное мнение о наличии скидок
Ошибочное мнение о наличии скидок при проверке состояния страхового полиса приведет к появлению вопроса «Почему потерялись скидки на ОСАГО?». Ошибочное мнение может возникнуть в следующей ситуации:
- неверно рассчитан период предоставления скидок – максимальный период предоставления скидок равняется периоду действия имеющегося страхового полиса;
- использование неточных сведений о водительском удостоверении – если по какой-либо причине осуществлена замена водительского удостоверения, то при самостоятельной проверке сведений о скидках, информация об их наличии не будет отражена на мониторе компьютера, и у водителя возникнет мысль, будто потерялся КБМ.

Страховка без ограничений по водителям
Этот вариант страховки позволяет страхователю вписать в ОСАГО неограниченное количество водителей (это является весомым достоинством для юридического лица). Однако после оформления такого страхового полиса не действуют индивидуальные скидки по ОСАГО у водителей, вписанных в страховой полис.
Потерялся КБМ после ДТП
Участие владельца машины или водителя в ДТП может послужить причиной для снижения размера скидок по действующему страховому полису. Это может произойти в ситуации, когда виновником аварии будет признан владелец/водитель машины.
Если виновником аварии является другая сторона, то водителю машины, попавшей в ДТП, потребуется представить страховой компании документ, подтверждающий его невиновность. Таким документом является оригинал либо копия протокола о ДТП, составленного инспектором ГИБДД. После предоставления документа о невиновности по случаю ДТП, страховая компания скидки по ОСАГО вернет.
Способы возврата скидок
Чтобы самостоятельно скидку по ОСАГО вернуть, следует придерживаться следующего порядка действий:
- установить причину обнуления КБМ, проверив на сайте РСА информацию по действующему страховому полису;
- сравнить обнаруженную информацию со сведениями, указанными на бланках старых страховых полисов ОСАГО;
- написать жалобу на страховщика или заявление на восстановление скидок и передать его в РСА или Центробанк РФ;
- подать иск в суд – это последний способ для восстановления скидок, его рекомендуется использовать, если обращение в РСА или Центробанк не принесло положительного результата.

В процессе восстановления скидок, водитель может избавиться от необходимости выяснения отношений со страховой компанией, сбора необходимой документации, ошибок при проверке наличия скидок, составления жалобы или заявления для РСА, составления иска в суд. Для этого потребуется обратиться к страховому брокеру, предоставляющему услуги по проверке или восстановлению скидок по ОСАГО.
Россияне из-за сбоя системы лишились скидок по ОСАГО — DRIVE2
Автомобилисты жалуются на многочисленные отказы страховщиков предоставлять скидки по ОСАГО за безаварийную езду. Страховщики же уверяют, что это единичные случаи и причина — в сбое автоматизированной системы данных.
«В мой адрес поступила информация от граждан, обеспокоенных следующей проблемой. Автовладельцы, желающие приобрести полис ОСАГО, при перезаключении договора обнаруживают, что утрачена так называемая скидка за безаварийную езду — КБМ (коэффициент бонус-малус)… Множество граждан при проверке своих данных сталкиваются с тем, что имеющиеся в базе сведения некорректны, а это ведет к утрате права на скидку», — говорится в запросе депутата Госдумы Ярослава Нилова (ЛДПР), направленном президенту РСА Игорю Юргенсу и главе Центробанка Эльвире Набиуллиной (ЦБ регулирует сферу страхования).
С 2011 года все данные о скидках хранятся в единой автоматизированной информационной системе Российского союза автостраховщиков (РСА). Данные в нее вносятся только страховыми компаниями. Бонус-малус делит автомобилистов на классы в зависимости от стажа страхования, количества аварий либо их отсутствия — автолюбителям присваиваются понижающие или повышающие коэффициенты. С применением коэффициентов полис может быть на половину дешевле или в два с половиной раза дороже.
Страховые агенты, пожелавшие остаться неназванными, подтвердили «Известиям» нестабильность в работе базы страховщиков. « Проблемы с определением коэффициента бонус-малус возникают через одного клиента. Вот одну семью страхую не первый год: они все взрослые водители, никаких аварий, а скидку по ОСАГО система не выдает. Еще был случай — у одного клиента приписали зачем-то к фамилии лишний мягкий знак. Случайно это вскрылось, были большие проблемы с оформлением полиса. Это тоже говорит о качестве системы», — рассказал один из собеседников.
На одном из интернет-ресурсов, позволяющих проверить наличие скидки в системе РСА (kbm-osago.ru), звучат более жесткие комментарии в адрес страховщиков: «Объясните, я 25 лет за рулем без аварий. А с этой базой у меня 4-й класс (скидка 5% вместо максимальной — 50%). Где справедливость?»— недоумевает пользователь Сергей.
«У меня водительский стаж 19 лет, а КБМ не найден, возвращен стандартный класс. Почему?» — негодует пользователь Alex. «Достал уже этот бардак. Я считаю, что если стаж больше 10 лет и нет никаких данных об аварийности страхователя, то КБМ должен быть 0,5 по презумпции невиновности», — пишет Юрий.
В РСА признают сбои в своей базе, но упирают на то, что это единичные случаи. «В базу данных РСА ежегодно вносится более 40 миллионов записей, и, безусловно, такой массив не может быть идеально чистым. Но мы ведем постоянную работу по проверке базы и устранению ошибок. В случае неправомерного применения коэффициентов автовладельцы могут обратиться в РСА. Надо подчеркнуть, что КБМ эффективно применяется при расчетах стоимости полиса», — сообщили изданию в пресс-службе РСА.
Страховщики предполагают, что сбои могут быть связаны с ошибками самих водителей. «Если человек в течение года не страховался, то при заключении договора на следующий год история страхования начинается заново. Как и в случае с любой базой данных, при работе с базой РСА есть вероятность попадания в нее некорректных или неполных данных, опечаток и т.д. Нередко автомобилист, поменявший водительское удостоверение (например, при смене фамилии), забывает сообщить об этом своему страховщику, как того требуют правила страхования…», — объясняет начальник отдела методологии автострахования компании СОГАЗ Юрий Горцакалян.
Чтобы решить проблему, водителю рекомендуют вернуться к старой схеме, действовавшей до начала работы базы РСА, — обращаться в свои старые страховые компании со старыми полисами ОСАГО, собирать справки о безаварийной езде. «После исправления данных вы можете написать заявление в страховую компанию, с которой уже заключен договор, и она вернет вам переплаченную часть страховой премии.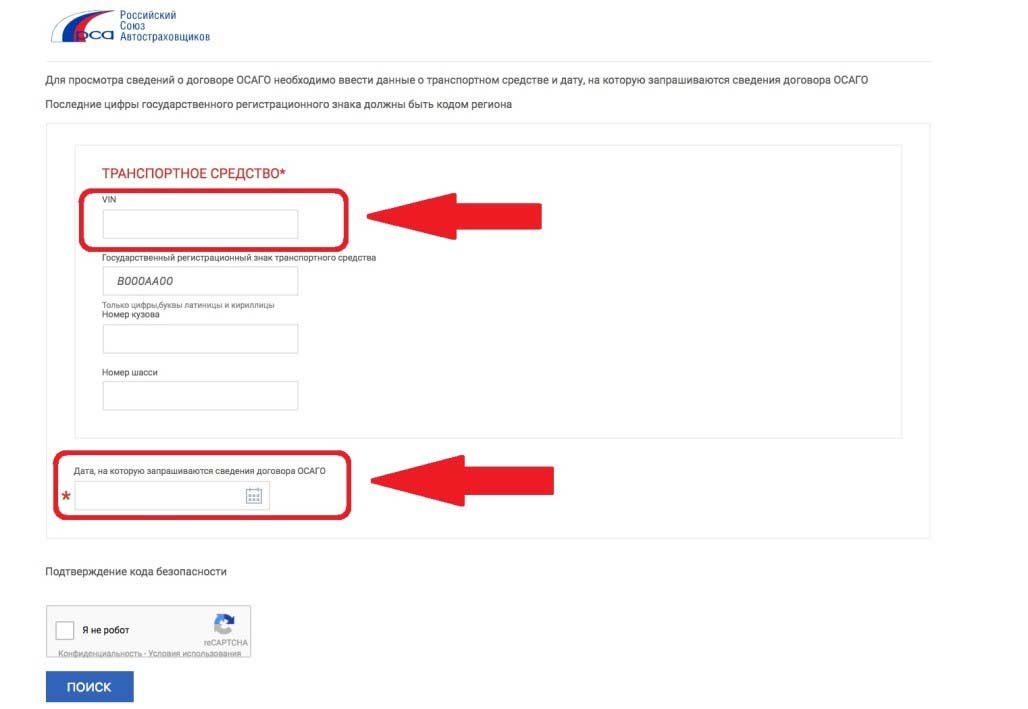 Но с этим лучше не затягивать — если срок действия заключенного договора истечет, вернуть по нему переплаченную премию уже нельзя», — добавил Горцакалян.
Но с этим лучше не затягивать — если срок действия заключенного договора истечет, вернуть по нему переплаченную премию уже нельзя», — добавил Горцакалян.
Как в Росгосстрах проверить полис ОСАГО онлайн по номеру, или найти полис
Электронный ресурс Российского Союза Страховщиков (РСА) предназначен для поиска данных застрахованных автовладельцев. В нем же можно проверить полис ОСАГО, выданный Росгосстрахом. Благодаря манипуляциям страхователь получает частичную или полную информацию о подлинности страховки. Кроме того, своевременная онлайн-проверка помогает защитить клиентов от многочисленных ошибок.
Почему так важно проверять полис ОСАГО
Страховая компания Росгосстрах входит в состав РСА, что говорит о том, что СК имеет лицензию на страховую деятельность. Это снижает риски попасть в мошеннические сделки. Но все-таки ситуации бывают разные. Например, при проверке полиса сотрудниками ГИБДД выясняется, что в Единой базе РСА отсутствуют данные.
Возможно, полис еще не активирован, так как после его покупки не прошло 3 дня, или страховка была утеряна. Также не исключено, что выданный полис фальшивый. Чтобы взаимодействовать на страховом рынке и создавалась Единая база РСА, где легко проверить законность действий СК.
Также не исключено, что выданный полис фальшивый. Чтобы взаимодействовать на страховом рынке и создавалась Единая база РСА, где легко проверить законность действий СК.
Проверка полиса ОСАГО Росгосстрах по номеру
Клиент может найти или узнать статус путем проверки полиса ОСАГО от Росгосстрах по номеру. Для этого предусмотрен специальный раздел, куда вводят следующую информацию:
- Серию бланка — данный параметр содержит три латинские буквы XXX, либо CCC, PPP или др. Такое обозначение характерно для бланков строгой отчетности. Серию можно найти как на бумажном ОСАГО, так и на электронном.
- Номер бланка — это уникальный набор цифр, использованный только раз в страховке. Содержит не больше десяти знаков.
Проверка по номеру займет одну минуту. Если удалось найти, то на сервисе будет отображен статус «Находится у страхователя». Значит, сделка действительна, и водитель может с уверенностью возить страховку ОСАГО с собой.
Бывают случаи, когда в базе клиенты могут и не найти номер, тогда необходимо обратиться к менеджеру, тому кто оформил бланк.
 Если покупка совершена онлайн, то свяжитесь с оператором по номеру 8-800-200-0-900 или 0530.
Если покупка совершена онлайн, то свяжитесь с оператором по номеру 8-800-200-0-900 или 0530.Узнать номер полиса по номеру автомобиля или VIN номеру
Чтобы проверить онлайн полис ОСАГО Росгосстрах на подлинность, нужно использовать сервис РСА. Главное отличие от предыдущего запроса, — что тут отображается полный объем информации, но и от Страхователя требуется больше сведений:
- VIN транспортного средства — персональный код из 17 знаков, встречаются цифры и латинские буквы, регулируется стандартами ISO.
- Регистрационный знак, номер кузова и шосси — указаны в заявке на ОСАГО, можно проверить по Свидетельству о регистрации транспортного средства.
- Дата запроса — может быть текущей или прошлой.
Если удастся найти страховой полис ОСАГО Росгосстрах, то в базе будет показана информация: серия и номер страховки, наименование компании, ограниченный доступ водителей или неограниченный. По времени обработка может занять больше времени, чем в первом варианте, но проверить полные сведения тоже не помешает.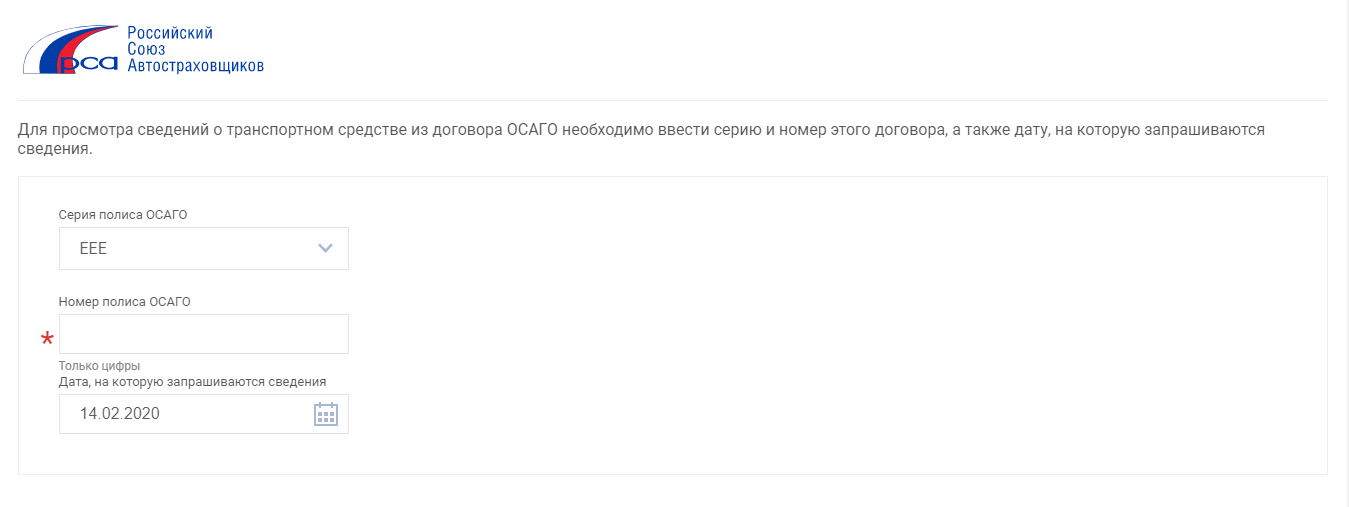
Иногда электронный сервис РСА перегружен, и проверить быстро не получится, тогда лучше зайти на официальный сайт позже или на следующий день.
Узнать номер застрахованного автомобиля по номеру полиса Росгосстрах
Допущенные ошибки легче исправить самостоятельно, и главное — вовремя. Бывает, что страхователи ошибаются при заполнении заявки, что впоследствии грозит штрафами. А иногда и в базе происходят сбои. На этот случай Росгосстрах предлагает проверить ОСАГО заранее по данным страховки. Введите:
- Серию и номер страхового бланка. В первом поле нужно найти три латинские буквы, во втором набрать десять цифр.
- В третьем поле требуется поставить дату, интересующую страхователя.
- С помощью кода безопасности и кнопки «Поиск» запрос уйдет на обработку.
Теперь автовладелец сможет найти данные транспортного средства. Это номерной знак, VIN и информацию по кузову.
При выявлении расхождений разрешено сделать корректировку через Личный кабинет Росгосстрах.
 Надо зайти на официальный сайт СК или в мобильное приложение, напротив полиса ОСАГО нажать на знак «карандаш». Внести изменения и сохранить. Такая онлайн-корректировка не приведет к увеличению стоимости, но придет новая страховка на указанный электронный адрес.
Надо зайти на официальный сайт СК или в мобильное приложение, напротив полиса ОСАГО нажать на знак «карандаш». Внести изменения и сохранить. Такая онлайн-корректировка не приведет к увеличению стоимости, но придет новая страховка на указанный электронный адрес.При обслуживании в офисе следует обратиться к менеджеру, который должен найти и проверить ошибку, затем скорректировать ее. Клиент получит новый страховой полис, который можно проверить в базе РСА после трех дней.
Форма проверки вписанных водителей
В страховке ОСАГО часто прописаны несколько водителей или даже больше, так как в Росгосстрах предусмотрен сервис по вводу неограниченного числа водительских удостоверений. Данная функция доступна не только в момент первоначальной покупки, но и позже. Это значит, что разрешено добавить в полис других водителей, но при этом стоит обратить внимание на цену, она подскочит.
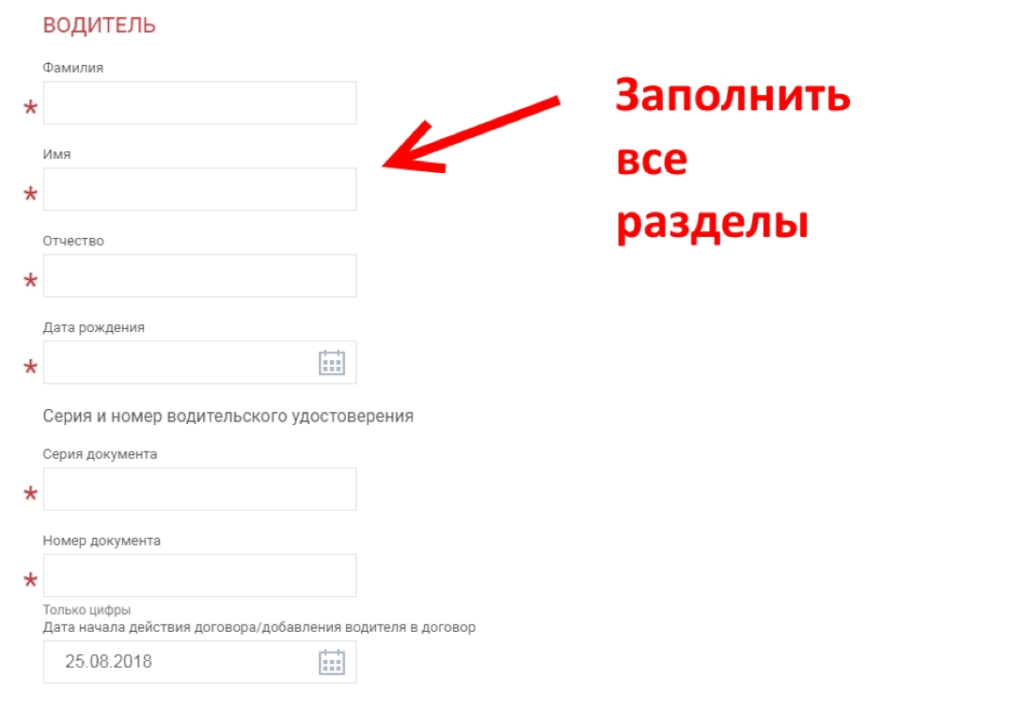
Чтобы найти и проверить правильность вписанных ФИО, надо действовать следующим образом:
- На официальном сайте РСА выбирают запрос по VIN и номерному знаку.
- Клиент получит полную информацию по ОСАГО.
- Далее в графе «водитель» можно проверить по номеру водительского удостоверения всех физических лиц, вписанных в бланк.

Такой способ проверки подходит для физических и юридических лиц. Даже если кто-то уже отстранен от управления транспортным средством, то придется переделывать Е-ОСАГО или дождаться окончания срока страхования.
возможно ли, онлайн-изменения — Рамблер/авто
Человеческий фактор никто не отменял даже в электронной системе хранения информации. Российский союз автостраховщиков (РСА), будучи связующим звеном между страховщиками и владельцами автомобилей, выступает одновременно и в качестве носителя данных о них, располагая требуемой информационной базой.
Но если автовладелец факт получения нового удостоверения водителя скроет от страховой компании, то в информационной базе РСА могут оказаться ошибочные данные. Подробнее об этом процессе читайте далее.
Как внести изменения в базу данных РСА при смене водительского удостоверения
Гражданское автострахование берёт под свою защиту человека, а не транспортное средство. Отсюда следует, что в информационный банк РСА должны вноситься все изменения, которые происходят с автовладельцем, особенно после смены им удостоверения водителя, хотя у его автомобиля никаких метаморфоз не наблюдается. Если необходимые поправки в базу не будут внесены, это чревато для автовладельца потерей им скидок, предоставляемых посредством коэффициента бонус-малус (КБМ), и некоторыми другими неприятностями.
Отсюда следует, что в информационный банк РСА должны вноситься все изменения, которые происходят с автовладельцем, особенно после смены им удостоверения водителя, хотя у его автомобиля никаких метаморфоз не наблюдается. Если необходимые поправки в базу не будут внесены, это чревато для автовладельца потерей им скидок, предоставляемых посредством коэффициента бонус-малус (КБМ), и некоторыми другими неприятностями.
Знаете ли вы? Как свидетельствует статистика, семейные водители на 10% реже попадают в автомобильной аварии, нежели холостые, а женщины в любом семейном статусе становятся виновницами ДТП на 10% чаще, чем мужчины.
Куда нужно обращаться
После замены документов, дающих право на вождение автомобиля, необходимо направить заявление об этом своим страховщикам, имеющим право доступа к информационному банку РСА. Если страхователи не осуществили действия по необходимой корректировке в информационной базе, нужно адресовать жалобу прямо в РСА. К ней нужно присовокупить копии документов, подававшихся параллельно с заявлением, а также копию самого заявления с зарегистрированным входящим номером.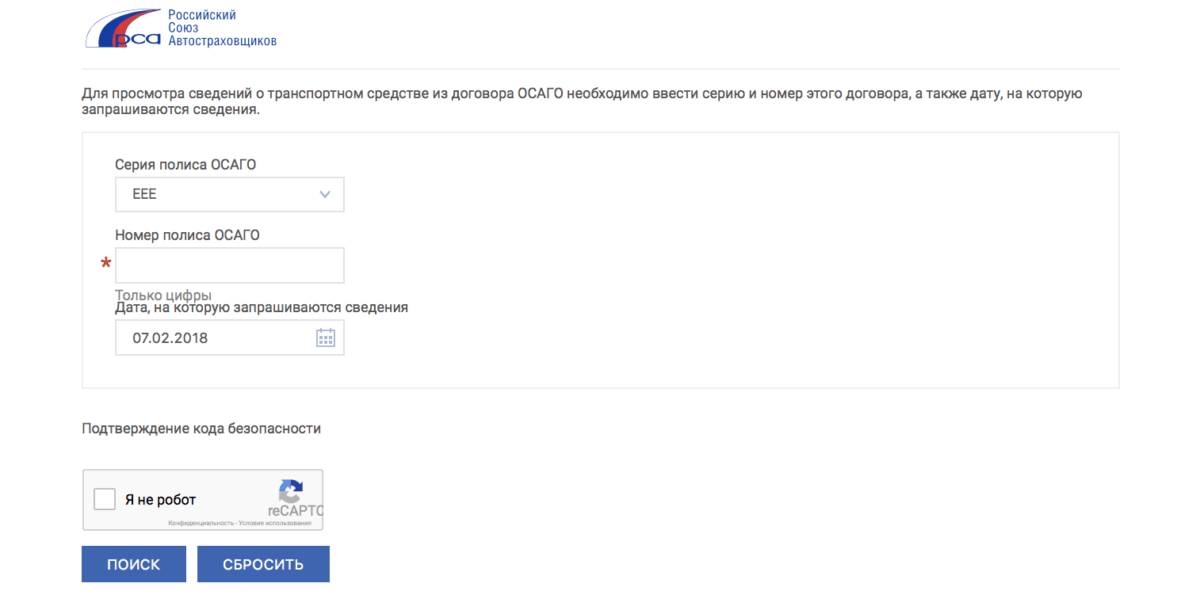
Имеется также возможность подачи аналогичной жалобы в Центральный банк. Если и эти жалобы останутся без удовлетворения и без указания причин этого, тогда имеется возможность адресовать свои претензии в суд. Для этого придётся заново подготовить требующиеся документы.
Кто вносит новые права в базу РСА
Полномочиями обновления сведений в связи с заменой водительских прав располагают исключительно страховые компании. РСА и ЦБ имеют лишь возможность воздействовать на них при наличии соответствующих жалоб на их ошибки.
Знаете ли вы? Впервые автомобильную страховку выписали ещё в позапрошлом веке — в 1898 г. Тогда американский автомобилист застраховал своё авто от столкновения с транспортом на конной тяге.
Список необходимых документов
Заявление страховщикам в связи с заменой ВУ об обновлении данных в информационном банке РСА сопровождается:
действующим страховочным договором;паспортной копией;удостоверением водителя;копией или оригиналом прежних страховых договоров.
Как внести изменения в базу данных РСА после замены прав
Каждый из страховщиков располагает своей формой написания заявлений. Однако автовладельцы вольны составлять прошения и произвольно. Закон предписывает изучение заявлений, длящееся не дольше 30 суток. На протяжении этого периода страховые менеджеры обязаны изучить все поданные документы. Затем изменённые сведения поступают в банк данных РСА, а КБМ восстанавливается.
Важно! Восстановление КБМ имеет своим следствием возврат средств, переплаченных автовладельцем из-за случившихся искажений в базе данных. Эти деньги переводятся на банковскую карту водителя.
Что нужно для сохранения КБМ
Сохранность КБМ после смены свидетельства о вождении гарантирует сообщение об этом страховщикам.
Сервисы для восстановления КБМ в базе РСА онлайн
Сегодня практически все фирмы, занимающиеся страхованием, располагают в Сети своими сайтами, посредством которых можно общаться со страховыми менеджерами онлайн. Имеется официально зарегистрированный сайт и у РСА, на котором автовладелец имеет возможность получить стандартный образец заявления на реабилитацию прежнего коэффициента. После заполнения этого заявления оно отсылается на электронную почту, где и рассматривается.
После заполнения этого заявления оно отсылается на электронную почту, где и рассматривается.
Онлайн-сервисы страховых компаний
Как уже говорилось, большинство страховщиков располагают собственными сайтами со специализированными онлайн-сервисами. Посредством их после заполнения требуемых образцов имеется возможность в онлайн-режиме решить вопрос возвращения КБМ.
Как внести данные в базу РСА самостоятельно
Уже подчёркивалось, что полномочиями изменять сведения в базе союза страховщиков располагает исключительно страховая компания. Сам союз страховщиков подобных прав не имеет. Водитель имеет возможность самостоятельно лишь рассчитать величину КБМ. Во всех остальных случаях нужно решать вопрос только со страховщиками.
Узнайте, какие бывают страховки на автомобиль.
Внесение исправлений в КБМ через страховую компанию
В случае, когда автовладелец уверен, что в отношении него в процессе вычисления величины КБМ допущено искажение фактов, ему нужно направить ходатайство своим страховщикам. Это можно осуществить посредством специальных онлайн-сервисов восстановления величины КБМ, исправляющих допущенные огрехи бесплатно.
Это можно осуществить посредством специальных онлайн-сервисов восстановления величины КБМ, исправляющих допущенные огрехи бесплатно.
Как с гарантией сделать восстановление КБМ за несколько дней
Лучше всего это осуществить посредством платных услуг, оказываемых профессиональными юристами.
Куда подавать заявление о восстановлении КБМ через РСА
Имеется возможность посредством Интернета отправить ходатайство о восстановлении КБМ на электронную почту РСА: [email protected]. Отослать документы можно и с помощью заказного письма по адресу: ул. Люсиновская, 27, кор. 3, Москва, 115093. По этому же адресу имеется возможность лично принести заявление и требуемые документы.
Важно! По статистике, наиболее часто искажённые размеры КБМ возникают вследствие именно замены водительских удостоверений и несвоевременного сообщения об этом событии страховщикам.
Откуда берётся ошибка значения КБМ в базе АИС
В качестве коэффициента поправок в процессе составления страховочного договора ОСАГО КБМ предоставляет дисциплинированным автомобилистам, не допустившим ДТП, скидки на покупку договора страхования по 5% ежегодно (но не свыше 50% совокупно). Инициаторы автоаварий, наоборот, наказываются увеличивающими коэффициентами в пределах от 1,4 до 2,45.
Инициаторы автоаварий, наоборот, наказываются увеличивающими коэффициентами в пределах от 1,4 до 2,45.
Однако при изменившихся данных паспорта, выдаче нового удостоверения водителя или завершении функционирования страховой фирмы информация о скидочных коэффициентах способна быть в банке данных в искажённом виде.
Видео: как восстановить исправить неправильный КБМ в базе РСА
Для дисциплинированного водителя, накопившего солидные страховочные бонусы благодаря безаварийной езде, способна стать досадным ударом потеря этих цифр вследствие искажения данных в информационной базе РСА. Но этого легко избежать, если сразу вслед за заменой прав на вождение автомобиля сообщить об этом своим страховщикам.
Анализ главных компонентов с отсутствующими данными | Себ Бейли
Сравнение алгоритмов отсутствующих оценок pcaMethods Анализ главных компонентов (PCA) — это метод статистического анализа, который можно использовать для попытки «объяснить» закономерности в данных и оценить уровень структуры данных. Входными данными для PCA может быть любой набор числовых переменных, однако они должны быть масштабированы относительно друг друга, и традиционный PCA не будет принимать какие-либо отсутствующие точки данных.
Входными данными для PCA может быть любой набор числовых переменных, однако они должны быть масштабированы относительно друг друга, и традиционный PCA не будет принимать какие-либо отсутствующие точки данных.
Точки данных будут оцениваться по тому, насколько хорошо они вписываются в главный компонент (ПК) на основе меры дисперсии в наборе данных.У каждой точки данных будет ПК, который лучше всего подходит. Таким образом, PCA можно рассматривать как своего рода кластерный анализ.
Каждый компьютер объяснит часть структуры данных (если таковая имеется!). Компоненты, которые объясняют 85% дисперсии (или те, где находятся пояснительные данные), можно считать наиболее важными точками данных.
Как упоминалось выше, традиционный PCA не принимает отсутствующие точки данных, однако пакет в R под названием pcaMethods реализует ряд дополнительных методов оценки.
Недостающие баллы оцениваются путем проецирования известных баллов обратно в «основное пространство», т. е. если есть определенная степень вариации, проявляемая в x, y, вероятно, изменится таким образом на основе предыдущих данных. Главное подпространство — это область вокруг модели, т.е. если она попадает в область значимости линейной регрессии.
е. если есть определенная степень вариации, проявляемая в x, y, вероятно, изменится таким образом на основе предыдущих данных. Главное подпространство — это область вокруг модели, т.е. если она попадает в область значимости линейной регрессии.
Алгоритмы
Эти методы являются мощными инструментами для запуска PCA с отсутствующими наборами данных, но их следует использовать с осторожностью и обращать внимание на количество недостающих данных, которое может принять каждый метод.Мои тесты показали, что если вы превысите эти значения, оценки, присвоенные каждому компьютеру, будут нечетными.
svd
- Стандартная функция prcomp
- Не работает с отсутствующими данными!
svdImpute
- Оценивает недостающие значения как линейную комбинацию наиболее значимых переменных
- Должен быть линейным, поэтому, если данные построены линейно, они могут быть намного более точными, но если они не линейно распределены, это бесполезно
- Итерационный
- Толерантность к отсутствию данных> 10%
ppca
- Вероятностный / вероятностный подход
- Предполагает нормальное распределение
- Толерантность к отсутствию данных ~ 15%
bpca
- Байесовский Вероятностный подход
- Может выдерживать> 10% отсутствующих данных
- Более слабый с большим количеством отсутствующих данных, но более точный в оценке
NLPCA
- Обратный нелинейный
- Отсутствующие данные представлены в виде нейронной сети
Nipals
- Нелинейное итерационное оценивание Частичные наименьшие квадраты
- Толерантность к небольшому количеству отсутствующих данных (5%)
- Исключает «внутренние продукты»
- По умолчанию для отсутствующих данных
- Перекрестная проверка
Общие сведения о PCA (анализ основных компонентов) | Тони Ю
Итак, как это работает такое волшебство? Есть либо объяснение линейной алгебры, либо интуитивное. Здесь мы выберем интуитивно понятный, но если вы хотите проверить математику, этот пост в блоге отличный.
Здесь мы выберем интуитивно понятный, но если вы хотите проверить математику, этот пост в блоге отличный.
PCA творит чудеса, неоднократно задавая и отвечая на следующие вопросы:
- В самом начале процесса PCA спрашивает, какая самая сильная основная тенденция в наборе функций (мы назовем этот компонент 1)? Позже мы визуализируем это несколькими способами, поэтому не беспокойтесь, если сейчас это непонятно.
- Следующий PCA спрашивает, какая вторая по силе основная тенденция в наборе функций также не коррелирует с компонентом 1 (мы будем называть его компонентом 2)?
- Затем PCA спрашивает, какая третья по силе основная тенденция в наборе функций также не коррелирует с обоими компонентами 1 и 2 (мы назовем это компонентом 3)?
- И так далее…
Как он находит эти основные тенденции? Если вы когда-либо гуглили PCA, вы, вероятно, видели что-то похожее на следующую картинку:
Простой пример PCA На картинке наши данные представлены черными точками. Итак, какова самая сильная основная тенденция? Мы можем подойти к этому так, как если бы это была проблема линейной регрессии: самый сильный тренд — это линия наилучшего соответствия (синяя линия). Итак, синяя линия — это компонент 1. Вы можете спросить, почему синяя линия — это компонент 1, а не красная линия? Помните, что компонент 1 — это главный компонент с наибольшей дисперсией (поскольку наибольшая дисперсия соответствует наивысшему потенциальному сигналу).
Итак, какова самая сильная основная тенденция? Мы можем подойти к этому так, как если бы это была проблема линейной регрессии: самый сильный тренд — это линия наилучшего соответствия (синяя линия). Итак, синяя линия — это компонент 1. Вы можете спросить, почему синяя линия — это компонент 1, а не красная линия? Помните, что компонент 1 — это главный компонент с наибольшей дисперсией (поскольку наибольшая дисперсия соответствует наивысшему потенциальному сигналу).
Связь линейной регрессии полезна, потому что она помогает нам понять, что каждый главный компонент представляет собой линейную комбинацию отдельных функций. Так же, как модель линейной регрессии представляет собой взвешенную сумму наших характеристик, которая наиболее точно соответствует нашей целевой переменной, главные компоненты также являются взвешенными суммами наших характеристик. За исключением этого случая, это взвешенные суммы, которые лучше всего отражают основные тенденции в нашем наборе функций.
Возвращаясь к нашему примеру, мы можем визуально увидеть, что синяя линия захватывает больше отклонений, чем красная линия, потому что расстояние между синими линиями с галочкой больше, чем расстояние между красными линиями.Расстояние между помеченными линиями — это приблизительное значение дисперсии, зафиксированной нашим главным компонентом — чем больше черные точки, наши данные, изменяются вдоль оси главного компонента, тем большую дисперсию он фиксирует.
Теперь для компонента 2 мы хотим найти второй по силе базовый тренд с добавленным условием, что он не коррелирует с компонентом 1. В статистике тренды и данные, которые ортогональны (то есть перпендикулярны) друг другу, не коррелированы.
Ортогональные данные Посмотрите на график слева.Я нарисовал две особенности: одну синюю, а вторую — красную. Как видите, они ортогональны друг другу. Все вариации синего элемента — горизонтальные, а все изменения красного — вертикальные. Таким образом, когда синий элемент изменяется (по горизонтали), красный элемент остается полностью постоянным, поскольку он может изменяться только по вертикали.
Круто, поэтому для того, чтобы найти компонент 2, нам просто нужно найти компонент с максимально возможной дисперсией, который также ортогонален компоненту 1.Поскольку наш предыдущий пример PCA был очень простым с двумя измерениями, у нас есть только один вариант для компонента 2 — красная линия. На самом деле у нас, вероятно, есть множество функций, поэтому нам нужно будет учитывать множество измерений при поиске наших компонентов, но даже тогда процесс остается тем же.
PCA четко объяснил —Когда, зачем, как его использовать и важность функций: Руководство по Python | Серафейм Лукас
- Метод PCA особенно полезен при обработке данных, где существует multi — коллинеарность между функциями / переменными .
- PCA можно использовать, когда размеры входных объектов велики (например, много переменных).
- PCA также можно использовать для удаления шума и данных сжатия .

Пусть X будет матрицей, содержащей исходные данные с формой [n_samples, n_features] .
Вкратце, анализ PCA состоит из следующих шагов :
- Во-первых, исходные входные переменные, хранящиеся в
X, имеют z-шкалы для каждой исходной переменной (столбецX) имеет нулевое среднее значение и стандартное отклонение. - Следующий шаг включает построение и собственное разложение ковариационной матрицы
Cx = (1 / n) X'X(в случае данных с z-оценкой ковариация равна корреляционной матрице, поскольку стандартное отклонение всех характеристик 1). - Собственные значения затем сортируются в порядке убывания , представляющего уменьшение дисперсии в данных (собственные значения равны дисперсии — я докажу это ниже, используя Python в параграфе 6).
- Наконец, проекция (преобразование) исходных нормализованных данных на сокращенное пространство PCA получается путем умножения (скалярный продукт) исходных нормализованных данных на ведущее собственных векторов ковариационной матрицы, то есть ПК.
- Новый уменьшил пространство PCA максимизирует отклонение исходных данных .Чтобы визуализировать прогнозируемые данные, а также вклад исходных переменных, на совместном графике мы можем использовать биплот .

Существует верхняя граница из значимых компонентов , которые можно извлечь с помощью PCA . Это связано с рангом матрицы ковариации / корреляции ( Cx ). Имея матрицу данных
Имея матрицу данных X с формой [n_samples, n_features / n_variables] , ковариация / корреляционная матрица будет [n_features, n_features] с максимальным рангом , равным мин (n_samples min , n_features) .
Таким образом, мы можем иметь максимум мин (n_samples, n_features) значащие PC компоненты / измерения из-за максимума ранга ковариационной / корреляционной матрицы.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
import pandas as pd
from sklearn.preprocessing import StandardScaler
plt.style.use '(' ggplot данные
iris = datasets.load_iris ()
X = iris.data
y = iris.target # Z-оценка характеристик
scaler = StandardScaler ()
scaler.
X = scaler.transform (X) # Модель PCA
pca = PCA (n_components = 2) # оценить только 2 ПК
X_new = pca.fit_transform (X) # спроецировать исходные данные в пространство PCA
 fit (X)
fit (X) Давайте нарисуем данные до и после преобразования PCA , а также цвета кодируйте каждую точку (образец), используя соответствующий класс цветка (y) .
fig, axes = plt.subplots (1,2) оси [0] .scatter (X [:, 0], X [:, 1], c = y)Вывод PCA приведенного выше кода .
axes [0] .set_xlabel ('x1' )
axes [0] .set_ylabel ('x2')
axes [0] .set_title ('Before PCA') axes [1] .scatter (X_new [:, 0], X_new [:, 1], c = y). )
axes [1] .set_xlabel ('PC1')
axes [1] .set_ylabel ('PC2')
axes [1] .set_title ('After PCA') plt.show ()
Мы можем видеть, что в пространстве PCA отклонение равно , максимизированному вдоль PC1 (объясняет 73% отклонения) и PC2 (объясняет 22% отклонения). Вместе они объясняют 95%. ( столбец
Вместе они объясняют 95%. ( столбец X ) имеет нулевое среднее значение и единичное стандартное отклонение, мы имеем:
Λ выше хранит собственные значения ковариационной матрицы исходного пространства / набора данных .
Проверить с помощью Python
Доказательство максимальной дисперсии можно также увидеть, оценив ковариационную матрицу для уменьшенного пространства :
np.cov (X_new.T) array ([[ 2.93808505 e + 00 , 4.83198016e-16],
[4.83198016e-16, 9.20164904e-01 ]])
Мы видим, что эти значения (на диагонали у нас есть дисперсии) равны и фактические собственные значения ковариации, хранящиеся в pca.объясненная_вариантность_ :
массив pca.
([2.93808505, 0.49])
 explained_variance_
explained_variance_ Важность каждого признака отражается величиной из соответствующих значений в собственных векторах (чем выше величина — тем важнее ).
Давайте найдем наиболее важных функций:
print (abs (pca.components_)) [[0,52106591 0,26934744 0,5804131 0,56485654]
[0,37741762 0,566 0.02449161 0,06694199]] Здесь
pca.components_имеет форму[n_components, n_features]Таким образом, если посмотреть на PC1 (первый главный компонент), который является первой строкой[[0,52106591 0,26934744 0,5804131 0,56485654]мы можем сделать вывод, что функции 1, 3 и 4 являются наиболее важными для PC1. Точно так же мы можем заявить, что feature 2 и , затем 1 — это наиболее важные для PC2.
Подводя итог, мы смотрим на абсолютные значения компонентов собственных векторов, соответствующих наибольшим собственным значениям k . В sklearn компоненты отсортированы по объясненной дисперсии. Чем больше эти абсолютные значения, тем больший вклад конкретная характеристика вносит в этот главный компонент.
Двухуровневая диаграмма — лучший способ визуализировать all-in-one после анализа PCA .
В R есть реализация, но в python нет стандартной реализации, поэтому я решил написать для этого свою собственную функцию :
def biplot (score, coeff, y):
'' '
Автор: Серафейм Лукас, [email protected]
Входные данные:
баллов: прогнозируемые данные
coeff: собственные векторы (ПК)
y: метки классов
'' 'xs = score [:, 0] # проекция на PC1
ys = score [:, 1] # проекция на PC2
n = коэфф.
для s, l в перечислении (классы):
plt.scatter (xs [y == l], ys [y == l], c = colors [s], marker = markers [s] ]) # цвет на основе группы
для i в диапазоне (n):
# отобразите в виде стрелок оценки переменных (каждая переменная имеет оценку для ПК1 и одну для ПК2)
plt.arrow (0, 0, coeff [i, 0], coeff [i, 1], color = 'k', alpha = 0.9, linestyle = '-', linewidth = 1.5, overhang = 0.2)
plt.text (coeff [i, 0] * 1.15, coeff [ i, 1] * 1.15, "Var" + str (i + 1), color = 'k', ha = 'center', va = 'center', fontsize = 10)plt.xlabel ("PC {}". format (1), size = 14)
plt.ylabel ("PC {}". format (2), size = 14)
limx = int (xs.max ()) + 1
limy = int (ys.max ()) + 1
plt.xlim ([- limx, limx])
plt.ylim ([- limy, limy])
plt.grid ()
plt.tick_params (axis = 'both', which = 'both', labelsize = 14)Вызов функции (сначала необходимо запустить начальные блоки кода, в которые мы загружаем данные радужной оболочки и выполняем анализ PCA):
import matplotlib as mplДвухуровневый график PCA с использованием моей пользовательской функции.
mpl.
двухплотность (X_new [:, 0: 2], np.transpose (pca.components_ [0: 2,:]), y)
plt.show ()Мы можем снова проверить визуально , что a) дисперсия максимальна и b) , что признаки 1, 3 и 4 являются наиболее важными для PC1. Аналогично, feature 2 и , затем 1 — это наиболее важные для PC2.
Кроме того, стрелки (переменные / характеристики), которые указывают в то же направление , указывают корреляцию между переменными, которые они представляют, тогда как стрелки, идущие в противоположных направлениях указывают на контраст между переменными, которые они представляют.
Проверьте выше, используя код :
# Var 3 и Var 4 чрезвычайно положительно коррелирован с
np.corrcoef (X [:, 2], X [:, 3]) [1, 0]
0.9628654314027957 # Var 2 и Var 3 отрицательно коррелирован с
np.corrcoef (X [:, 1], X [:, 2]) [1,0]
-0.42844010433054014Вот и все, ребята! Надеюсь, вам понравилась эта статья!
Руководство по статистике GraphPad Prism 9
На вкладке параметров диалогового окна необходимо принять два основных решения, которые могут сильно повлиять на результаты и выводы PCA.Если вы не понимаете, почему вам нужно поступить иначе, мы рекомендуем выполнить PCA для стандартизованных данных и использовать параллельный анализ для выбора количества компонентов.
Метод
Наиболее важным решением является выполнение PCA для стандартизованных или центрированных данных.
PCA по стандартизованным данным
Если у вас нет особых причин поступить иначе, это рекомендуемый подход.
Как это работает: перед выполнением PCA переменные преобразуются так, чтобы каждая переменная имела среднее значение 0 и стандартное отклонение 1. Это помещает все переменные в одну шкалу, так что при нахождении ПК каждая переменная взвешивается одинаково. . Математически
Xстандартизированный = (Xraw — X̄) / sx
, где X — среднее значение, а sx — стандартное отклонение значений переменных.
PCA по центрированным данным
Если все ваши переменные находятся в одних и тех же единицах измерения, вы можете захотеть выполнить PCA для центрированных данных, также называемого PCA для ковариационной матрицы. Бывают случаи, когда это правильный выбор, но редко.
Как это работает: Перед выполнением PCA переменные преобразуются так, чтобы каждая переменная имела среднее значение 0 с неизменным стандартным отклонением.
Xcentered = (Xraw — X̄)
, где X — среднее значение переменных.
Метод выбора количества главных компонентов
Выбор основных компонентов — это процесс, который определяет, сколько «измерений» будет иметь набор данных с уменьшенной размерностью после PCA. В некоторых случаях Prism предоставляет результаты только для выбранных ПК (нагрузки, собственные векторы, матрица вклада переменных, матрица корреляции переменных и ПК, оценки ПК и матрица вклада наблюдений).
Prism предлагает четыре подхода к выбору количества основных компонентов:
Параллельный анализ (рекомендуется)
Параллельный анализ — это элегантная смоделированная процедура для выбора количества ПК для включения путем определения точки, в которой ПК неотличимы от ПК, генерируемых смоделированным шумом.
1.Prism моделирует большое количество наборов данных (по умолчанию 1000, но можно указать другое число).Каждый смоделированный набор данных содержит такое же количество переменных (столбцов) и наблюдений (строк), что и входные данные.
a. Для каждой моделируемой переменной данные генерируются путем выборки из многомерного нормального распределения со средним значением = 0.
b. Стандартное отклонение для каждой моделируемой переменной равно стандартному отклонению соответствующей переменной в таблице входных данных
2. PCA выполняется для каждого смоделированного набора данных
3. Для каждого ПК среднее собственное значение вычисляется для всех смоделированных наборов данных
4.Для каждого ПК верхний процентиль (95-й процентиль по умолчанию) вычисляется с использованием собственных значений из всех смоделированных наборов данных
5. Для каждого ПК Prism сравнивает собственное значение из входных данных с верхним процентилем, вычисленным из смоделированных наборов данных
6 .
Обратите внимание, что если вы выбираете параллельный анализ для определения количества ПК, на осыпной диаграмме будут отображаться смоделированные собственные значения вместе с собственными значениями из ваших данных.
Выбрать ПК на основе собственных значений
Классически выбирались ПК с собственными значениями больше 1. Это называется правилом Кайзера. Мотивация использования «1» в качестве порогового значения заключается в том, что для стандартизованных данных стандартное отклонение (и дисперсия) каждой переменной равно 1. Собственные значения для ПК представляют собой отклонение, которое ПК представляет от исходных данных. Таким образом, если величина вариации, вносимая каждой исходной переменной (или столбцом), равна 1, ПК с собственным значением меньше 1 объясняет меньшую вариацию, чем один столбец данных.
Prism также включает опции, позволяющие выбрать другое значение отсечки или просто оставить первые k ПК с наибольшими собственными значениями (k можно указать в опциях).
Выбрать ПК на основе процента от общей объясненной дисперсии
Другой распространенной (классической) процедурой выбора количества ПК является сохранение ПК с наибольшими собственными значениями, которые в совокупности объясняют указанный процент от общей дисперсии. Обычные варианты целевого процента от общей дисперсии — 75% и 80%.
Выбрать все ПК
Последний вариант — заставить Prism сообщать обо всех компьютерах. Это редко бывает полезно, но может быть полезно для обучения или исследования нишевых данных.
Анализ главных компонентов (PCA) | Руководство по PCA
Эта статья была опубликована в рамках Data Science Blogathon.
ВведениеОдним из самых востребованных и не менее сложных методов машинного обучения является анализ главных компонентов (PCA).
В этой статье для начала мы интуитивно разберемся, что такое PCA, как это делается, для чего. Сообщение, в котором мы углубимся в математику, лежащую в основе PCA: линейные алгебраические операции, механику PCA, ее значение и приложения.
СодержаниеВремя рассказа
- Отношение сигнал / шум (SNR)
- Проклятие размерности
- Пошаговый подход к проведению PCA
- Улучшение SNR с помощью PCA
- Линейные алгебраические операции
- Пример разложения по сингулярным числам
- Уменьшение размерности
- Переменное уменьшение
- Факторная нагрузка и выбор переменных
- Может ли PCA применяться ко всем видам данных?
Давайте начнем с вопроса, какую радиостанцию вы любите слушать? Я люблю слушать 104.
Ось абсцисс представляет частоты FM, и у нас есть 104.8 как желаемый шаг радиоканала.
Теперь, по мере того, как мы отдаляемся от требуемой FM-частоты либо на более высокой, либо на более низкой стороне, мы начинаем получать нежелательные сигналы, то есть радиопередача искажается из-за шума. Другими словами, мы получаем максимальную громкость или амплитуду нашей необходимой станции на этой конкретной частоте 104,8, но объем канала падает, когда мы отклоняемся от 104,8. Это подводит нас к концепции шума и сигнала.
В статистике интересующий нас сигнал или имеющаяся информация хранится в разбросе (или дисперсии) данных.
Отношение сигнал / шум (SNR)У нас есть математическое пространство, состоящее из двух измерений x 1 и x 2 , и данные между этими двумя измерениями разбросаны, как показано ниже.
Когда мы смотрим на пространство только с точки зрения x 1 , тогда величина разброса находится в диапазоне от x 1 min до x 2 max, то есть информационного содержания, захваченного x 1 .И, глядя на данные из x 2 , сигнал или величина разброса, выраженная посредством x 2 измерений, находится в диапазоне от x 2 min и x 2 max.
При совместном анализе этих данных с учетом x 1 и x 2 мы видим, что существует больший разброс, содержащий информацию о том, как x 1 и x 2 влияют друг на друга.
Следовательно, при сопоставлении точек данных, присутствующих в обоих измерениях, мы видим, что в математическом пространстве присутствует ковариация, которая показывает, что x 1 и x 2 влияют друг на друга.
Следовательно, сигнал — это все допустимые значения для переменной в диапазоне между ее соответствующими минимальными и максимальными значениями и шум, представленный разбросом точек данных по линии наилучшего соответствия.Это необъяснимое изменение данных вызвано случайными факторами.
Цель PCA — максимизировать или увеличить содержание этого сигнала и уменьшить содержание шума в данных.
Источник: gstatic.com
Теперь перейдем к пониманию другой цели PCA.
Проклятие размерностиПри построении модели с Y в качестве целевой переменной эта модель принимает две переменные в качестве предикторов x 1 и x 2 и представляет их как:
Y = f (X 1 , X 2 )
В этом случае модель, которой является f, предсказывает взаимосвязь между независимыми переменными x 1 и x 2 и зависимой переменной Y.При построении этой модели с использованием любого из доступных алгоритмов мы, по сути, вводим x 1 и x 2 в качестве входных данных для алгоритма. Это означает, что этот алгоритм получает входные данные из информационного содержания, присутствующего в переменной x 1 , и информационного содержания, представленного в переменной x 2 в качестве двух параметров.
Все алгоритмы предполагают, что эти параметры, которые делают математическое двумерное пространство вместе с целевой переменной, независимы друг от друга, то есть x 1 и x 2 не влияют друг на друга.
Когда X 1 и X 2 зависят друг от друга, эти переменные в конечном итоге взаимодействуют друг с другом. Другими словами, между ними существует корреляция. Когда две независимые переменные очень сильно взаимодействуют друг с другом, то есть коэффициент корреляции близок к 1, мы предоставляем алгоритму ту же информацию в двух измерениях, что является не чем иным, как избыточностью.Это излишне увеличивает размерность свойств математического пространства. Когда у нас слишком много измерений больше, чем требуется, мы подвергаемся проклятию размерности .
Влияние того, что имеет больше измерений в модели, которая представляет собой не что иное, как наличие мультиколлинеарности в данных, может привести к переобучению, и это подвергает модель ошибкам дисперсии, то есть модель может не работать или прогнозировать новые невидимые данные.
PCA также помогает уменьшить эту зависимость или избыточность между независимыми измерениями.
Позже мы подробно рассмотрим, как PCA помогает уменьшить эту избыточность в размерах. Узнав, что такое PCA, давайте теперь исследуем, как PCA работает вместе с математикой, участвующей в нем.
Пошаговый подход к проведению PCAPCA по существу вращает оси координат таким образом, что ось фиксирует почти все информационное содержание или отклонения.На клипе ниже это наглядно показано. Мы рассмотрим шаг за шагом, как этого добиться.
Источник: medium.com
Выше мы видели, что в модель вводятся два независимых параметра X 1 и X 2 . В реализации Python мы будем делать это с помощью model.fit (x1, x2). Как мы уже знаем, модель фиксирует только индивидуальную соответствующую информацию, доступную в предикторах, а не совместный разброс, который намного богаче, поскольку он показывает, как эти две переменные изменяются вместе.
Цель PCA — захватить эту ковариационную информацию и передать ее алгоритму построения модели. Мы рассмотрим этапы процесса PCA.
Работу и реализацию PCA можно получить из моего репозитория Github.
Шаг 1. Стандартизация независимых переменныхКогда мы применяем Z-оценку к данным, мы по существу центрируем точки данных в начале координат.Что мы подразумеваем под центрированием данных?
Из приведенной выше диаграммы частот FM предположим, что 104,8 — это центральное значение, то есть среднее или среднее значение, представленное полосой x, а другие частоты — значениями xi. При преобразовании этих значений xi в Z-оценку, где Z = (x i — x bar) / стандартное отклонение
Возьмите любое значение x i , расстояние в единицах стандартного отклонения, то есть на сколько стандартных отклонений это значение x i от центрального значения или среднее значение, которое представлено Z-оценкой этого x i точек.
Когда x i больше среднего, тогда это вычисленное расстояние в терминах стандартного отклонения или, другими словами, Z-оценка будет положительной, а Z-оценка будет отрицательной, когда xis меньше x- бар. Поскольку Z-оценка становится от положительной до отрицательной при переходе через центральное значение, а затем подставляя это x i = x-bar в формулу Z-score = (x i — x bar) / стандартное отклонение, числитель становится равным нулю. .
Короче говоря, процесс стандартизации заключается в том, что мы берем все точки данных и сдвигаем среднее значение частот с 104.8, чтобы обнулить. Это означает, что данные по всем измерениям вычитаются из их средних значений, чтобы сдвинуть точки данных в начало координат.
После этой стандартизации все частоты (точки данных), которые были на более высокой стороне среднего значения 104,8, стали положительными значениями, а все частоты, которые были на более низкой стороне среднего значения 104,8, стали отрицательными значениями.
Шаг 2. Создание ковариационной или корреляционной матрицы для всех измеренийНа следующем этапе мы собираем информацию о ковариации между всеми измерениями, вместе взятыми.В исходном двухмерном пространстве данные выглядят следующим образом: x 1 -bar и x 2 -bar в качестве соответствующих средних значений и имеют ковариации между x 1 и x 2 .
Когда мы стандартизируем точки данных, происходит то, что центральные значения становятся измерениями, а данные разбросаны вокруг них. При этом преобразовании x i s в Z-оценки значения x i сдвигаются из исходного пространства в новое пространство, где данные центрируются, а все оси представляют собой полосу x 1 , x 2 бар, x 3 бар и т. Д.
В этом новом математическом пространстве мы находим ковариацию между x 1 и x 2 и представляем ее в виде матрицы и получаем что-то вроде следующего:
Эта матрица представляет собой числовое представление того, сколько информации содержится между двумерным пространством X 1 и X 2 .
В матрице элементы на диагоналях представляют собой дисперсию или разброс x 1 с самим собой и x 2 с самим собой, подразумевающим, сколько информации содержится в самой переменной.Следовательно, диагонали почти всегда будут близки к единице, поскольку это показывает, как переменная ведет себя с собой.
Степень сигнала или информации указывается недиагональными элементами. Они указывают на корреляцию между x 1 и x 2 , то есть как эти два взаимодействуют или изменяются друг с другом. Положительная корреляция предполагает положительно линейную зависимость, а значение отрицательной корреляции представляет отрицательную линейную зависимость. Крайне важно использовать эту недавно обнаруженную информацию в качестве исходных данных для построения нашей модели.
Шаг 3: Собственное разложениеПроцесс собственного разложения преобразует исходную ковариационную матрицу между X1 и X2 в другую матрицу, которая выглядит как матрица ниже.
В этой новой матрице диагонали равны единице, а элементы вне диагонали становятся близкими к нулю. Эта матрица представляет собой то математическое пространство, в котором вообще нет информационного содержания. Все информационное содержание находится на оси, это означает, что ось наблюдала за всем информационным содержанием, и новое математическое пространство теперь пусто.
В ходе этого процесса мы получаем два вывода, как показано ниже:
собственных векторов: это новые измерения нового математического пространства, а
Собственные значения: это информационное содержание каждого из этих собственных векторов. Это разброс или дисперсия данных по каждому из собственных векторов.
Ниже мы подробно рассмотрим значение и математику этих выходных сигналов собственных векторов и собственных значений, а также то, как оси поглощают все сигналы.
Шаг 4. Отсортируйте собственные векторы, соответствующие их собственным значениям
Матрица ковариации главных компонентов
Математически мы получаем ковариационную матрицу из заданной матрицы, умножая матрицу на ее транспонированную форму.
Ниже приведен пример связи матрицы и парного графика.На парном графике мы видим, что существует некоторая корреляция между двумя переменными, и эта связь представлена в числовой форме в этой ковариационной матрице. Следовательно, эта матрица отражает, сколько информации содержится в математическом пространстве, а парный график является графическим изображением того же самого.
Диагонали на парном графике показывают, как переменные ведут себя друг с другом, а недиагонали показывают взаимосвязь между двумя переменными так же, как это было для ковариационной матрицы.Поскольку к настоящему времени мы знаем, что эта внедиагональная информация еще не подается в модель, и наша гипотеза заключается в том, что как только мы отправим эти недиагональные сигналы также в модель, производительность модели будет лучше, и это отразится на производстве. .
Улучшение SNR с помощью PCA
Первым шагом к проведению PCA было центрирование наших данных, что было сделано путем стандартизации только независимых переменных.
Для двумерных данных приведенный выше визуальный элемент показывает, что раньше оси были соответствующими полосами по оси x, а теперь это новые измерения. Данные по-прежнему ориентированы так же, как и в исходном пространстве, только теперь они стали центрированными.
Эта информация преобразуется в ковариационную матрицу. К этой ковариационной матрице мы применяем собственную функцию, которая является функцией линейной алгебры.Измерения преобразуются с помощью этой алгебры в новый набор измерений.
При применении собственной функции теоретически происходит поворот математического пространства. Преобразование представляет собой поворот осей в математическом пространстве и определяет два новых измерения, которые называются собственными векторами: E1 и E2.
Эти собственные векторы — не что иное, как главные компоненты.
Величина разброса, которую захватывает каждый собственный вектор, или, другими словами, дисперсия по каждому из собственных векторов выражается в собственных значениях. Итак, в нашем двумерном пространстве собственный вектор E1 имеет связанное собственное значение ev1, а собственный вектор E2 имеет другое связанное собственное значение ev2.
В исходном пространстве у нас было два измерения x 1 и x 2 , и, следовательно, мы получим два собственных вектора. Количество собственных векторов или главных компонентов (или новых измерений) всегда будет равно количеству измерений в исходном пространстве.Каждый из этих собственных векторов будет ортогональным, то есть будет под углом 90 градусов друг к другу. Это выходит за рамки нашего воображения и объема статьи, чтобы визуально изобразить, как компоненты находятся под углом 90 градусов друг к другу для пространства более высоких измерений.
На графике ниже мы видим, что собственные векторы, представленные на оси, содержат всю информацию, и в математическом пространстве нет точек данных (или отсутствуют нулевые сигналы), кроме осей. Вся информация фиксируется в собственном векторе E1 или E2.
Как только мы построим ковариационную матрицу этих собственных векторов, мы получим матрицу, подобную приведенной ниже.
Это показывает, что диагональные элементы, имеющие значение 1, объясняют всю информацию, присутствующую в данных, а недиагональные элементы, теоретически со значением нуля, показывают отсутствие сигнала или информационного содержания. В действительности недиагональные элементы будут близки к нулю, а не совсем нулю.
Исходные точки данных теперь представлены красными точками на новых измерениях.
А теперь давайте поработаем руками, углубившись в математику, лежащую в основе PCA.
Линейные алгебраические операции для PCAPCA — это, по сути, один из типов разложения по сингулярным значениям (SVD).
Это почти то же самое, что и СВД, математически это может быть сложной задачей. Для нашей цели здесь мы рассмотрим самый минимум математических операций, необходимых для понимания работы PCA.
Любая матрица, скажем, A размерности m * n, где m — количество строк, а n — количество столбцов:
Далее можно разложить следующим образом:
, где U и V — ортогональные матрицы с ортонормированными собственными векторами, выбранными из AAᵀ и AᵀA соответственно.S — диагональная матрица с r элементами, равными корню положительных собственных значений AAᵀ или Aᵀ A (в любом случае обе матрицы имеют одинаковые положительные собственные значения)
Диагональные элементы состоят из сингулярных значений.
Не волнуйтесь, мы посмотрим, что делают эти греческие термины, на примере ниже. Во-первых, нам нужно понять следующие два свойства матриц:
Ортогональная матрица:
Здесь U и V — ортогональные матрицы.Это означает, что когда мы берем перекрестное произведение (или, с математической точки зрения, скалярное произведение) U и V, то результат равен нулю.
U * V = 0: ортогональные векторы
С точки зрения статистики, две матрицы ортогональны, что означает, что эти матрицы независимы друг от друга.
Ортонормированная матрица:
Когда матрица ортонормирована, это означает, что: а) матрицы ортогональны и б) определитель (то значение, которое помогает нам зафиксировать важную информацию о матрице в виде единственного числа) равно 1.
| U | = 1, | V | = 1 и U * V = 0: ортонормированные векторы
В случае, если у нас есть квадратная матрица, то есть имеющая одинаковое количество строк и столбцов, ее можно разделить на меньшие значения следующим образом:
Математически то, что означают собственные векторы и собственные значения, основано на спектральной теореме. Теорема следующая (мы не будем здесь приводить и доказывать теорему):
Источник: слайд-плеер
Пример разложения по сингулярным числамДавайте посмотрим, как это делается.Скажем, A — это корреляционная матрица, как показано ниже:
Шаг 1: Как рассчитать матрицы U и V? Мы получаем его транспонированием матрицы A.
Шаг 2: Результирующие, которые мы получаем, используя матрицу A и ее матрицу транспонирования Aᵀ, равны:
U = A * Aᵀ и
В = Aᵀ * A
Шаг 3: Возьмите U = A * Aᵀ и вычислите собственные векторы и связанные с ними собственные значения.
Шаг 4: Используя выходные данные, являющиеся собственным вектором, полученным на шаге 3, мы вычисляем матрицу сингулярных значений S.Это сингулярное значение является квадратным корнем из собственных векторов.
Шаг 5: Умножая три матрицы: U, S и V, как показано ниже, конечная матрица такая же, как исходная матрица A.
Мы видим, что матрица S представляет собой нечто похожее на матрицу, полученную нами при выполнении PCA. Он показывает, что значения на диагонали являются информацией или сигналом, поскольку все оси поглощают всю информацию, а недиагональные элементы не имеют никакого содержания сигнала.
Уменьшение размерности
Вторичной целью PCA является уменьшение размерности. Как мы можем уменьшить размеры, не теряя информационного содержания, содержащегося в переменных? Всякий раз, когда мы удаляем любую из функций, мы теряем сигнал или информацию, доступную в данных.
Как видно выше, когда существует более сильная линейная зависимость между переменными X 1 и X 2 , то измерения становятся более избыточными.
Следовательно, когда существует сильное взаимодействие между измерениями данных, вместо того, чтобы отбрасывать одну из переменных и терять информацию, мы можем использовать PCA и создать одно составное измерение из двух исходных измерений и отбросить оба исходных объекта.
Что будет делать PCA? PCA создает первый главный компонент, PC1, а второй главный компонент, PC2, находится под углом 90 градусов к первому компоненту.
Оба эти компонента поглощают все ковариации, присутствующие в математическом пространстве.
Однако это все равно не помогает нам отбросить размеры. Число измерений по-прежнему равно двум, как и исходное число измерений. Но здесь мы можем кое-что сделать, мы можем узнать совокупную информацию по всем основным компонентам, вместе взятым.
Первый главный компонент, PC1, всегда будет содержать максимум, т.е. основную часть ковариационной информации, и будет иметь наивысшее собственное значение, указывающее, что этот компонент захватывает максимум информации.Мы можем выполнить следующие шаги, чтобы выполнить уменьшение размерности:
Расположите все главные компоненты (т.
Основываясь на этом сводном графике, мы можем отбросить те компоненты, которые не имеют существенного вклада в общие собственные значения.
Как мы читаем приведенный выше сюжет? График показывает, что первый главный компонент захватывает около 64% информации, присутствующей в исходном математическом пространстве i.е. объясняет ~ 64% разброса данных. Если взять вместе первые два компонента, общая объясненная вариация близка к 78%, а при взятии первых трех компонентов совокупная объясненная вариация составляет ~ 90%, а ~ 99% вариации улавливается первыми четырьмя основными компонентами. Другие основные компоненты 5, 6 и 7 несущественны, поскольку они не вносят никакого вклада, предполагая, что они не объясняют большой объем информации и, следовательно, могут быть опущены.
Таким образом, начиная построение модели с семью измерениями, мы можем отбросить три незначительных главных компонента и построить модель с оставшимися четырьмя компонентами.Используя этот анализ, мы уменьшаем семимерное математическое пространство до четырехмерного математического пространства и теряем лишь несколько процентных пунктов данных. Следовательно, мы можем уменьшить размерность данных без потери большого количества информации.
Мы также можем применить другой метод, известный как линейный дискриминантный анализ (LDA), чтобы уменьшить размерность, хотя этот метод выходит за рамки статьи.
Переменная редукцияТеперь, помимо увеличения отношения сигнал / шум (SNR) и уменьшения размерности, есть еще одна цель PCA.Это уменьшить переменные.
Это делается путем группировки переменных на основе сходства (т.е. переменных, имеющих высокую корреляцию), которые группируются вместе. Эта цель PCA полезна в бизнес-задачах, когда требуется классифицировать данные по n-м классам, а n не предопределено, короче говоря, в задачах сегментации.
Чтобы увидеть и понять, как это работает, мы подойдем к механике PCA иначе, чем то, что мы видели выше.Шаги, необходимые для расчета PCA, такие же, как описано выше, но отличается концептуальная основа для достижения PCA.
Допустим, мы строим модель, имеющую десять предикторов Xs с целевой переменной Y, и исходное уравнение для модели, основанное на алгоритме линейной регрессии, выглядит следующим образом:
Y = B 1 X 1 + B 2 X 2 +… + B n X n + C
Где X — размеры данных и не являются независимыми друг от друга
Мы применяем PCA для управления новыми функциями или компонентами, основанными на этих исходных десяти переменных X.PCA также рассчитываются как линейные комбинации исходных переменных (Xs) для генерации осей (также известных как главные компоненты) и имеющих веса Wi.
Итак, регрессия, основанная на ПК, или называемая регрессией главных компонентов, имеет следующее линейное уравнение:
Y = W 1 * PC 1 + W 2 * PC 2 +… + W 10 * PC 10 + C
Где ПК: ПК1, ПК2….
При интерпретации главных компонентов полезно знать корреляции исходных переменных с главными компонентами. Мы выводим новые измерения (или компоненты) таким образом, чтобы производные переменные были линейно независимыми друг от друга и, следовательно, учитывалась мультиколлинеарность, присутствующая в данных.
Причина, по которой производные измерения независимы друг от друга, заключается в условии ортогональности матриц, которое мы видели выше, в котором указано, что перекрестное произведение U и V равно нулю (следовательно, подразумевается, что корреляция равна нулю между этими двумя матрицами.)
Теперь переключим передачи, чтобы понять, как производятся ПК и как оцениваются веса, и, самое главное, что они означают и как это помогает уменьшить переменные.
Как определяются размеры ПК?
Чтобы применить PCA, мы берем стандартизованные (Z-баллы) каждой из переменных, скажем, она обозначается Z_X1, Z_X2… .
На основе этих стандартизированных Z-оценок и коэффициентов (которые являются бета-версиями) мы получаем размеры PC1, PC2… PC10. Каждому из этих производных компонентов соответствует следующее уравнение:
B 11 * Z_X 1 + B 12 * Z_X 2 +… + B 110 * Z_X 10
B 21 * Z_X 1 + B 22 * Z_X 2 +… + B 210 * Z_X 10
….
B 101 * Z_X 1 + B 102 * Z_X 2 +… + B 1010 * Z_X 10
Как оцениваются эти веса или бета-версии?
Бета-версии оцениваются так, чтобы они удовлетворяли следующим критериям:
Corr (ПК и , ПК и ) ~ 0
Вар (ПК 1 ) + Вар (ПК 2 ) +… Вар (ПК 10 ) = 10
Вар (ПК 1 )> Вар (ПК 2 )>… Вар (ПК 10 )
Собственные векторы квадратной матрицы корреляционной матрицы такие же, как у бета-коэффициентов (или коэффициентов), вычисленных в PC Regression, и, следовательно, эти два взаимосвязаны.
Таким образом, мы получили от применения процесса PCA:
i) PC1, PC2,… .PC10 является производным и независимыми функциями от X1, X2… X10
Как видно выше, если исходные переменные равны 10, будет создано 10 новых измерений.
ii) Corr между ПК: Corr (Pc i , PC j ) ~ 0, где i и j разные
iii) Var (X 1 ) + Var (X 2 ) + Var (X 3 )… + Var (X 10 ) = Var (PC 1 ) + Var (PC 2 ) +… Вар (ПК 10 )
Это означает, что общая вариация, объясняемая всеми X, также объясняется главными компонентами.Если каждая переменная объясняет или способствует одной вариации, то общая вариация, объясняемая всеми переменными, равна 10 и
.iv) Var (PC 1 )> Var (PC 2 )>… Var (PC 10 ), что указывает на то, что первый компонент PC 1 объясняет максимальное отклонение, за которым следует изменение, объясненное PC 2 и так далее.
Как уменьшить количество переменных с помощью PCA?
Во-первых, мы вычисляем корреляцию между стандартизированным значением Z-балла каждой из переменных с каждым из основных компонентов.
Итак, предположим, что первая переменная X имеет Z-оценку Z_X1, а PC1 является первым компонентом, корреляция между этими двумя значениями есть не что иное, как бета-версия, то есть B11.
Следующее в линейном уравнении для первого компонента:
PC1 = B11 * Z_X1 + B12 * Z_X2 +… .. + B110 * Z_X10
Бета-версии — это корреляция, поскольку они косвенно подразумевают, какой вклад X вносит в основные компоненты. В приведенном выше уравнении B11 означает, какая часть X1 вносит вклад в PC1.
Поскольку Z_X — это стандартизированные оценки, то есть все переменные X находятся на одной шкале, поэтому теперь мы можем сравнить бета-версии (коэффициенты) каждой из оценок.
Если B12 является самым высоким, то можно сделать вывод, что Z_X2 имеет максимальный вклад (или максимальное влияние) на первый компонент, PC1 и Z_X2 имеют высокую корреляцию с PC1.
В итоге, чем выше бета-версии (или коэффициенты), тем больше видно, какие X имеют большее влияние на ПК.Следовательно, на основе этих коэффициентов или корреляции, вычисленной между стандартизованными оценками и основными компонентами, мы можем получить переменные, которые имеют максимальный вклад.
Факторные нагрузки и как выбрать переменные?
Коэффициенты или вычисленная корреляция между стандартизованными оценками и основными компонентами также известны как факторные нагрузки. В следующей таблице показаны нагрузки для пяти производных компонентов ПК для исходных 10 переменных X, где Bis означает соответствующие корреляции.
Таблица 1:
PC1 PC2 PC3 PC4 PC5 Z_X1 B11 = 0,12 B21 B31 B41 B51 Z_X2 B12 = 0,55 B22 B32 B42 B52 Z_X3 B13 = 0. B23 B33 B43 B53 Z_X4 B14 = 0,85 B24 B34 B44 B54 Z_X5 B15 = 0,17 B25 B35 B45 B55 Z_X6 B16 = -0,34 B26 B36 B46 B56 Z_X7 B17 = -0.11 B27 B37 B47 B57 Z_X8 B18 = 0,15 B28 B38 B48 B58 Z_X9 B19 = 0,74 B29 B39 B49 B59 Z_X10 B110 = 0,21 B210 B310 B410 B510 Эти загрузки помогают нам выбрать, какие переменные X имеют больший вклад в переменные ПК.
Переменные Z_X4, Z_X9 и Z_X2 для PC1 имеют более высокую корреляцию по сравнению с другими и, следовательно, можно сделать вывод, что эти три переменные имеют максимальный вклад в PC1 (независимо от того, положительная или отрицательная корреляция).
Теперь, исходя из этого, можно сказать, что корреляция между Z_X4 и PC1 выше, чем корреляция между Z_X9 и PC1.
Итак, когда Z_X4 имеет корреляцию с PC1; Z_X9 имеет корреляцию с PC1, а Z_X2 имеет корреляцию с PC1, тогда мы также можем сказать, что Z_X4, Z_X6 и Z_X2 имеют некоторую корреляцию между собой i.е. эти переменные сильно коррелированы друг с другом.
Следовательно, мы можем сгруппировать эти переменные, которые имеют максимальный вклад в соответствующий главный компонент, PC, и мы получим следующую таблицу.
Таблица 2:
PC1 Х9 Х4 Х2 PC2 Х3 Х5 Х7 Х10 PC3 Х1 Х2 Х8 Таблица 2 сообщает нам, какие переменные вносят максимальный вклад в соответствующий главный компонент.
Теперь, проанализировав эту таблицу, мы можем сделать следующие выводы: если переменная X3 вносит максимальный вклад в главный компонент, PC2, то она будет меньше вносить вклад в PC1 и PC3, потому что ПК независимы друг от друга.
В заключение, как только нагрузки сгруппированы на основе их вклада в ПК, тогда:
Переменные X в каждом из ПК имеют некоторую корреляцию между собой (как сказано выше в ПК1, переменные X9, X4 и X2 имеют некоторую корреляцию между собой, и аналогично другие переменные имеют корреляцию, присутствующую в соответствующих компонентах для ПК2 и ПК3)
Следовательно, на основе наибольшего вкладчика переменных в ПК мы можем выбрать (или выбрать) любую из переменных.Например, для PC1 наибольший вклад вносит X9. В случае, если мультиколлинеарность является проблемой, мы можем выбрать ту переменную, которая имеет наименьшую корреляцию среди всех переменных.
В случае, если имеется больше переменных, сгруппированных вместе, можно также выбрать две переменные для представления этого главного компонента.
Здесь следует предостеречь, так как в приведенном выше PC1 три переменные X9, X4, X2 имеют некоторую корреляцию между собой, тогда это может привести к проблеме мультиколлинеарности, присутствующей в самих компонентах ПК.Это проблема в задачах регрессии (например, линейной и логистической регрессии), поскольку эти параметрические методы могут привести к проблеме нестабильной оценки бета-значений (или коэффициентов), что является серьезным следствием мультиколлинеарности. В конечном итоге это может привести к переобучению модели, о чем свидетельствуют незначительные бета-версии (имеющие p-значение более 0,05), что слишком много переменных не влияют на точность модели.
Однако в бизнес-задачах, основанных на сегментации, это не проблема.
Следовательно, цель PCA состоит в том, чтобы сгруппировать переменную на основе сходства (имеющего высокую корреляцию), чтобы нагрузки, которые имеют высокий вклад (корреляцию), были сгруппированы вместе.
Можно ли использовать PCA для любого типа данных?PCA следует использовать только в определенных условиях. Данные должны иметь сильную линейную корреляцию между независимыми переменными. Разброс данных должен быть похож на любой из первых двух визуальных элементов, а не на последний визуальный элемент, изображенный на графике ниже.Короче говоря, для применения PCA в данных должна быть высокая мультиколлинеарность.
Источник: gstatic.com
Заключительные мыслиНа следующем рисунке очень кратко представлен PCA.
Источник: Виктор Лавренко и Чарльз Саттон, 2011 г.
Вывод для нас: PCA кормит двух птиц одной лепешкой:
Увеличивает сигнал или информационное содержание, предоставляемое алгоритму для построения модели, путем преобразования существующих измерений для увеличения отношения сигнал / шум.
Это помогает удалить зависимость, присутствующую в данных, путем удаления функций, которые содержат ту же информацию, что и другой атрибут, а производные компоненты независимы друг от друга.
Профиль Linkedin: linkedin.com/in/neha-seth-69771111
СвязанныеАлгоритм анализа главных компонентов (PCA)
PCA — это алгоритм машинного обучения без учителя, который пытается уменьшить размерность (количество функций) в наборе данных, при этом сохраняя столько же информация по мере возможности.Это делается путем нахождения нового набора функций под названием компонентов , которые являются составными частями исходных элементов, которые не коррелируют друг с другом. Они также ограничены так, что первый компонент учитывает максимально возможную изменчивость данных, второй компонент — второй наибольшая изменчивость и так далее.
В Amazon SageMaker PCA работает в двух режимах в зависимости от сценария:
обычный : для наборов данных с разреженными данными и умеренное количество наблюдений и особенностей.
рандомизировано : для наборов данных с большим числом наблюдений и особенностей. В этом режиме используется алгоритм аппроксимации.
PCA использует табличные данные.
Строки представляют наблюдения, которые вы хотите встроить в пространство более низкой размерности. В столбцы представляют объекты, для которых вы хотите найти сокращенное приближение. В алгоритм вычисляет ковариационную матрицу (или ее аппроксимацию распределенным образом), а также затем выполняет разложение по сингулярным значениям для этого резюме, чтобы получить главное компоненты.
Интерфейс ввода / вывода для алгоритма PCA
Для обучения PCA ожидает данных, предоставленных в канале поезда, и дополнительно поддерживает набор данных, переданный в тестовый набор данных, который оценивается окончательным алгоритмом.
recordIO-wrapped-protobufиCSV поддерживаются форматыдля тренировки.Вы можете использовать файловый или конвейерный режим для обучения моделей на данных, которые является форматируется какrecordIO-wrapped-protobufили какCSV.Для вывода PCA поддерживает
text / csv,application / jsonи Приложение/ x-recordio-protobuf.Результаты возвращаются либо в Приложение/ jsonилиприложение / формат x-recordio-protobufс вектором «проекций».Для получения дополнительной информации о форматах входных и выходных файлов см.
Рекомендация по экземпляру EC2 для PCA Алгоритм
PCA поддерживает вычисления как на GPU, так и на CPU.Какой тип экземпляра наиболее эффективен сильно зависит от специфики входных данных.
Образцы ноутбуков PCA
Для примера записной книжки, в которой показано, как использовать анализ основных компонентов SageMaker.
Руководство по созданию ключа безопасной загрузки Windows и управлению им
Эта страница полезна?
- 40 минут на чтение
Оцените свой опыт
да Нет
Любой дополнительный отзыв?
Отзыв будет отправлен в Microsoft: при нажатии кнопки отправки ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Этот документ помогает OEM-производителям и ODM-производителям создавать ключи и сертификаты безопасной загрузки и управлять ими в производственной среде. В нем рассматриваются вопросы, связанные с созданием, хранением и извлечением ключей платформы (PK), безопасных ключей обновления прошивки и сторонних ключей обмена ключами (KEK).
Примечание
Эти шаги не относятся к OEM-производителям ПК. Предприятия и клиенты также могут использовать эти шаги для настройки своих серверов для поддержки безопасной загрузки.
Требования Windows для UEFI и безопасной загрузки можно найти в разделе «Требования к сертификации оборудования Windows». Этот документ не вводит новых требований и не представляет официальную программу Windows. Он предназначен в качестве руководства, выходящего за рамки требований сертификации, для помощи в создании эффективных и безопасных процессов для создания ключей безопасной загрузки и управления ими.Это важно, потому что безопасная загрузка UEFI основана на использовании инфраструктуры открытого ключа для проверки подлинности кода перед тем, как разрешить его выполнение.
Ожидается, что читатель знает основы UEFI, основы безопасной загрузки (глава 27 спецификации UEFI) и модель безопасности PKI.
Требования, тесты и инструменты, проверяющие безопасную загрузку в Windows, доступны сегодня через Комплект сертификации оборудования Windows (HCK). Однако эти ресурсы HCK не касаются создания ключей для развертываний Windows и управления ими.В этом документе управление ключами рассматривается как ресурс, помогающий партнерам развертывать ключи, используемые микропрограммным обеспечением. Он не предназначен в качестве предписывающего руководства и не включает никаких новых требований.
На этой странице:
Этот документ служит отправной точкой в разработке готовых к работе ПК, заводских инструментов развертывания и основных передовых методов обеспечения безопасности.
1. Безопасная загрузка, Windows и управление ключами
Спецификация UEFI (Unified Extensible Firmware Interface) определяет процесс аутентификации выполнения микропрограммы, называемый Secure Boot.
Secure Boot основан на процессе инфраструктуры открытого ключа (PKI) для аутентификации модулей до того, как им будет разрешено выполнение. Эти модули могут включать драйверы микропрограмм, дополнительные ПЗУ, драйверы UEFI на диске, приложения UEFI или загрузчики UEFI. Благодаря аутентификации образа перед выполнением Secure Boot снижает риск атак вредоносных программ перед загрузкой, таких как руткиты.Microsoft полагается на UEFI Secure Boot в Windows 8 и более поздних версиях в рамках своей архитектуры безопасности Trusted Boot, чтобы повысить безопасность платформы для наших клиентов. Безопасная загрузка требуется для клиентских ПК с Windows 8 и более поздних версий, а также для Windows Server 2016, как определено в Требованиях совместимости оборудования Windows.
Процесс безопасной загрузки работает следующим образом, как показано на Рисунке 1:
- Компоненты загрузки микропрограммы: Микропрограмма проверяет, что загрузчик ОС является надежным (Windows или другая доверенная операционная система.)
- Загрузочные компоненты Windows: BootMgr, WinLoad, запуск ядра Windows. Загрузочные компоненты Windows проверяют подпись каждого компонента. Любые ненадежные компоненты не будут загружены, а вместо этого запустят исправление безопасной загрузки.
- Инициализация антивирусного и вредоносного ПО: Это программное обеспечение проверяется на наличие специальной подписи, выпущенной Microsoft, подтверждающей, что это надежный драйвер, критичный для загрузки, и запускается в самом начале процесса загрузки.
- Инициализация драйвера, критически важного для загрузки: Подпись всех драйверов, критичных для загрузки, проверяется как часть проверки безопасной загрузки в WinLoad.
- Инициализация дополнительной ОС
- Экран входа в Windows
Рисунок 1. Архитектура надежной загрузки Windows
Внедрение UEFI Secure Boot является частью архитектуры надежной загрузки Microsoft, представленной в Windows 8.1. Растущая тенденция в развитии эксплойтов вредоносных программ заключается в том, что путь загрузки является предпочтительным вектором атаки. От этого класса атак трудно защититься, поскольку продукты для защиты от вредоносных программ могут быть отключены вредоносным ПО, которое полностью предотвращает их загрузку.Благодаря архитектуре доверенной загрузки Windows и ее установлению корня доверия с помощью безопасной загрузки, клиент защищен от вредоносного кода, выполняющегося на пути загрузки, гарантируя, что только подписанный, сертифицированный «заведомо исправный» код и загрузчики могут выполняться перед операционной системой. сам грузит.
1.
PKI устанавливает подлинность и доверие в системе. Безопасная загрузка использует PKI для двух целей высокого уровня:
- Во время загрузки, чтобы определить, доверены ли модули ранней загрузки для выполнения.
- Для проверки подлинности запросов на обслуживание необходимо внести изменения в базы данных безопасной загрузки и обновления микропрограмм платформы.
PKI состоит из:
- Центр сертификации (ЦС), который выдает цифровые сертификаты.
- Регистрирующий орган, который проверяет личность пользователей, запрашивающих сертификат у ЦС.
- Центральный каталог, в котором хранятся и индексируются ключи.
- Система управления сертификатами.
1.2 Криптография с открытым ключом
Криптография с открытым ключом использует пару математически связанных криптографических ключей, известных как открытый и закрытый ключ. Если вы знаете один из ключей, вы не сможете легко вычислить, что это за другой.
В системе с открытым ключом безопасной загрузки у вас есть следующее:
1.2.1 Шифрование RSA 2048
RSA-2048 — асимметричный алгоритм шифрования. Пространство, необходимое для хранения модуля RSA-2048 в необработанном виде, составляет 2048 бит.
1.2.2 Самоподписанный сертификат
Сертификат, подписанный закрытым ключом, который соответствует открытому ключу сертификата, называется самозаверяющим сертификатом.
1.2.3 Центр сертификации
Центр сертификации (ЦС) выдает подписанные сертификаты, которые подтверждают идентичность субъекта сертификата и связывают эту идентичность с открытым ключом, содержащимся в сертификате. ЦС подписывает сертификат, используя свой закрытый ключ. Он выдает соответствующий открытый ключ всем заинтересованным сторонам в самозаверяющем сертификате корневого ЦС.
При безопасной загрузке центры сертификации (CA) включают OEM (или их представителей) и Microsoft.Центры сертификации генерируют пары ключей, которые образуют корень доверия, а затем используют закрытые ключи для подписи законных операций, таких как разрешенные модули EFI для ранней загрузки и запросы на обслуживание микропрограмм. Соответствующие открытые ключи поставляются встроенными в микропрограмму UEFI на ПК с включенной безопасной загрузкой и используются для проверки этих операций.
(Более подробная информация об использовании центров сертификации и обмене ключами доступна в Интернете, что относится к модели безопасной загрузки.)
1.2.4 Открытый ключ
Открытый ключ платформы поставляется на ПК и является общедоступным. В этом документе мы будем использовать суффикс «pub» для обозначения открытого ключа. Например, PKpub обозначает публичную половину PK.
1.2.5 Закрытый ключ
Для работы PKI необходимо безопасное управление закрытым ключом. Он должен быть доступен для нескольких высокопоставленных лиц в организации и находиться в физически безопасном месте с строгими ограничениями политик доступа.В этом документе мы будем использовать суффикс «priv» для обозначения закрытого ключа. Например, PKpriv указывает частную половину PK.
1.2.6 Сертификаты
В основном цифровые сертификаты используются для проверки происхождения подписанных данных, таких как двоичные файлы и т.
Цифровой сертификат обычно содержит на высоком уровне отличительное имя (DN), открытый ключ и подпись. DN идентифицирует объект — например, компанию — которая содержит закрытый ключ, соответствующий открытому ключу сертификата. Подписание сертификата закрытым ключом и размещение подписи в сертификате связывает закрытый ключ с открытым ключом.
Сертификаты могут содержать некоторые другие типы данных. Например, сертификат X.509 включает формат сертификата, серийный номер сертификата, алгоритм, используемый для подписи сертификата, имя центра сертификации, выдавшего сертификат, имя и открытый ключ объекта, запрашивающего сертификат и подпись ЦС.
1.2.7 Связывание сертификатов
Откуда: Цепочки сертификатов:
Рисунок 2: Цепочка из трех сертификатов
Пользовательские сертификаты часто подписываются другим закрытым ключом, например закрытым ключом ЦС.
Сертификат пользователя не обязательно должен быть подписан закрытым ключом корневого ЦС. Он может быть подписан закрытым ключом посредника, чей сертификат подписан закрытым ключом ЦС. Это экземпляр цепочки из трех сертификатов: сертификат пользователя, промежуточный сертификат и сертификат CA. Но частью цепочки может быть более одного посредника, поэтому цепочки сертификатов могут быть любой длины.
1.3 Требования PKI безопасной загрузки
Определенный UEFI корень доверия состоит из ключа платформы и любых ключей, которые OEM или ODM включают в ядро встроенного ПО.
1.3.1 Требования к безопасной загрузке
Для реализации безопасной загрузки необходимо учитывать следующие параметры:
- Требования заказчика
- Требования к аппаратной совместимости Windows
- Требования к генерации ключей и управлению.
Вам нужно будет выбрать оборудование для управления ключами безопасной загрузки, такое как модули безопасности оборудования (HSM), учесть особые требования к ПК для отправки правительствам и другим учреждениям и, наконец, процесс создания, заполнения и управления жизненным циклом различных безопасных загрузок. ключи.
1.3.2 Ключи, связанные с безопасной загрузкой
Ключи, используемые для безопасной загрузки:
Рисунок 3: Ключи, связанные с безопасной загрузкой
На рисунке 3 выше представлены подписи и ключи на ПК с безопасной загрузкой.
Авторизованная база данных (db) содержит открытые ключи и сертификаты, которые представляют доверенные компоненты микропрограмм и загрузчики операционной системы. База данных запрещенных сигнатур (dbx) содержит хэши вредоносных и уязвимых компонентов, а также скомпрометированные ключи и сертификаты и блокирует выполнение этих вредоносных компонентов.Сила этих политик основана на подписи микропрограмм с использованием Authenticode и инфраструктуры открытых ключей (PKI). PKI — это хорошо отлаженный процесс создания, управления и отзыва сертификатов, которые устанавливают доверие во время обмена информацией. PKI лежит в основе модели безопасности безопасной загрузки.
Ниже приводится более подробная информация об этих ключах.
1.3.3 Ключ платформы (ПК)
Согласно разделу 27.5.1 UEFI 2.3.1 Errata C, ключ платформы устанавливает доверительные отношения между владельцем платформы и встроенным ПО платформы.Владелец платформы регистрирует открытую половину ключа (PKpub) во встроенном ПО платформы, как указано в разделе раздела 7.2.1 UEFI 2.3.1 Errata C . Этот шаг переводит платформу в пользовательский режим из режима настройки. Microsoft рекомендует использовать ключ платформы типа
EFI_CERT_X509_GUIDс алгоритмом открытого ключа RSA, длиной открытого ключа 2048 бит и алгоритмом подписи sha256RSA. Владелец платформы может использовать типEFI_CERT_RSA2048_GUID, если пространство для хранения является проблемой.Открытые ключи используются для проверки подписей, как описано ранее в этом документе. Владелец платформы может позже использовать частную половину ключа (PKpriv):
- Чтобы сменить владельца платформы, вы должны перевести микропрограмму в определенный UEFI режим установки , который отключает безопасную загрузку.
- Для настольных ПК OEM-производители управляют PK и необходимой PKI, связанной с ним. Для серверов OEM-производители по умолчанию управляют PK и необходимой PKI.Корпоративные клиенты или клиенты серверов также могут настроить PK, заменив PK, доверенный OEM, на собственный PK, чтобы заблокировать доверие к прошивке UEFI Secure Boot самому себе.
1.3.3.1 Для регистрации или обновления ключа обмена ключами (KEK) Регистрация ключа платформы
Владелец платформы регистрирует открытую половину ключа платформы ( PKpub ), вызывая UEFI Boot Service SetVariable (), как указано в разделе 7.2.1 UEFI Spec 2.3.1, ошибка C, и перезагружая платформу.Если платформа находится в режиме настройки, то новый PKpub должен быть подписан с его аналогом PKpriv . Если платформа находится в пользовательском режиме, то новый PKpub должен быть подписан текущим PKpriv .
EFI_CERT_X509_GUID, то он должен быть подписан непосредственно PKpriv , а не закрытым ключом какого-либо сертификата, выпущенного под PK.1.3.3.2 Очистка ключа платформы
Владелец платформы очищает открытую половину ключа платформы ( PKpub ), вызывая UEFI Boot Service SetVariable () с размером переменной 0 и перезагружая платформу.Если платформа находится в режиме настройки, то пустая переменная не требует аутентификации. Если платформа находится в пользовательском режиме, то пустая переменная должна быть подписана текущим PKpriv ; подробности см. в разделе 7.2 (Службы переменных) в спецификации UEFI 2.3.1 Errata C. Настоятельно рекомендуется никогда не использовать рабочую версию PKpriv для подписания пакета для сброса платформы, поскольку это позволяет программно отключить безопасную загрузку. Это в первую очередь сценарий предпроизводственного тестирования.
Ключ платформы также можно очистить с помощью безопасного метода, зависящего от платформы.
Рисунок 4: Диаграмма состояния клавиш платформы
1.3.3.3 Поколение ПК
Согласно рекомендациям UEFI, открытый ключ должен храниться в энергонезависимом хранилище, устойчивом к подделке и удалению на ПК. Закрытые ключи остаются в безопасности у Партнера или в офисе безопасности OEM, и только открытый ключ загружается на платформу.Более подробная информация представлена в разделах 2.2.1 и 2.3.
Количество генерируемых ПК определяется владельцем платформы (OEM). Эти ключи могут быть:
По одному на ПК . Наличие одного уникального ключа для каждого устройства. Это может потребоваться для государственных учреждений, финансовых учреждений или других клиентов серверов с высокими требованиями к безопасности. Для генерации закрытых и открытых ключей для большого количества компьютеров может потребоваться дополнительное хранилище и вычислительная мощность.
По одному на модель . Наличие одного ключа на каждую модель ПК. Компромисс здесь заключается в том, что если ключ будет скомпрометирован, все машины в одной модели будут уязвимы. Microsoft рекомендует это для настольных ПК.
По одной на продуктовую линейку . Если ключ будет скомпрометирован, будет уязвима вся линейка продуктов.
Один на OEM . Хотя это может быть проще всего в настройке, если ключ будет скомпрометирован, каждый компьютер, который вы производите, окажется уязвимым. Чтобы ускорить работу на заводе, ПК и, возможно, другие ключи могут быть предварительно сгенерированы и сохранены в безопасном месте.
1.3.3.4 Замена ключа ПК
Это может потребоваться, если PK будет скомпрометирован, или по требованию клиента, который по соображениям безопасности может решить зарегистрировать свой собственный PK.
Переназначение ключей может быть выполнено либо для модели, либо для ПК в зависимости от того, какой метод был выбран для создания ПК. Все новые ПК будут подписаны с помощью вновь созданного ПК.
Для обновления PK на производственном ПК потребуется либо обновление переменной, подписанное существующим PK, заменяющее PK, либо пакет обновления прошивки.OEM-производитель также может создать пакет SetVariable () и распространить его с помощью простого приложения, такого как PowerShell, которое просто изменяет PK. Пакет обновления прошивки будет подписан защищенным ключом обновления прошивки и проверен прошивкой. При обновлении прошивки для обновления PK следует позаботиться о сохранении KEK, db и dbx.
На всех ПК не рекомендуется использовать PK в качестве ключа безопасного обновления прошивки. Если PKpriv скомпрометирован, то это будет ключ безопасного обновления прошивки (поскольку они одинаковы).В этом случае обновление для регистрации нового PKpub может оказаться невозможным, поскольку процесс обновления также был скомпрометирован.
На ПК с SOC есть еще одна причина не использовать PK в качестве безопасного ключа обновления прошивки. Это связано с тем, что ключ безопасного обновления прошивки постоянно сгорает в предохранителях на компьютерах, которые соответствуют требованиям сертификации оборудования Windows.
1.3.4 Ключ обмена ключами (KEK) Ключи обмена ключами устанавливают доверительные отношения между операционной системой и микропрограммным обеспечением платформы.Каждая операционная система (и, возможно, каждое стороннее приложение, которому необходимо взаимодействовать с прошивкой платформы) регистрирует открытый ключ ( KEKpub ) во встроенном ПО платформы.
1.3.4.1 Регистрация ключей обмена ключами
Ключи обмена ключами хранятся в базе данных подписей, как описано в 1.4 Базы данных подписей (Db и Dbx)). База данных подписей хранится как аутентифицированная переменная UEFI.
Владелец платформы регистрирует ключи обмена ключами, вызывая SetVariable (), как указано в Разделе 7.2 (Variable Services) в соответствии со спецификацией UEFI 2.3.1 Errata C. с установленным атрибутом
EFI_VARIABLE_APPEND_WRITEи параметром Data, содержащим новый ключ (и), или путем чтения базы данных с помощью GetVariable (), добавив новый ключ обмена ключами к существующие ключи, а затем записать базу данных с помощью SetVariable (), как указано в разделе 7.2 (Службы переменных) в соответствии со спецификацией UEFI 2.3.1 Errata C без установленного атрибутаEFI_VARIABLE_APPEND_WRITE.Если платформа находится в режиме настройки, переменную базы данных подписей не нужно подписывать, но параметры для вызова SetVariable () все равно должны быть подготовлены, как указано для аутентифицированных переменных в разделе 7.
.1.3.4.2 Очистка KEK
Есть возможность «очистить» (удалить) KEK. Обратите внимание, что если PK не установлен на платформе, «очистить» запросы не требуется. Если они подписаны, то для очистки KEK требуется пакет, подписанный PK, а для очистки db или dbx требуется пакет, подписанный любым объектом, присутствующим в KEK.
1.3.4.3 Microsoft KEK
Microsoft KEK требуется для включения отзыва плохих образов путем обновления dbx и, возможно, для обновления db для подготовки к новым образам, подписанным Windows.
Включить Microsoft Corporation KEK CA 2011 в базу данных KEK со следующими значениями:
- Хэш сертификата SHA-1:
31 59 0b fd 89 c9 d7 4e d0 87 df ac 66 33 4b 39 31 25 4b 30.- GUID владельца подписи:
{77fa9abd-0359-4d32-bd60-28f4e78f784b}.- Microsoft предоставит сертификат партнерам, и он может быть добавлен как подпись типа
EFI_CERT_X509_GUIDилиEFI_CERT_RSA2048_GUID.Сертификат Microsoft KEK можно загрузить по адресу: https://go.microsoft.com/fwlink/?LinkId=321185.
1.3.4.4 KEKDefault Поставщик платформы может предоставить набор ключей обмена ключами по умолчанию в переменной KEKDefault. См. Раздел 27 спецификации UEFI.3.3 для получения дополнительной информации.
1.3.4.5 OEM / сторонний KEK — добавление нескольких KEK
Клиентами владельцам платформ не обязательно иметь собственный KEK. На ПК, отличных от Windows RT, OEM может иметь дополнительные KEK, чтобы позволить дополнительному OEM или доверенному стороннему лицу управлять db и dbx.
1.3.5 Ключ обновления микропрограммы безопасной загрузки Ключ безопасного обновления микропрограммы используется для подписи микропрограммы, когда ее необходимо обновить.
Согласно публикации NIST 800-147 обновление прошивки на месте должно поддерживать все элементы рекомендаций:
Любое обновление флэш-памяти прошивки должно быть подписано создателем.
Прошивкадолжна проверять подпись обновления.
1.3.6 Создание ключей для безопасного обновления прошивки
Тот же ключ будет использоваться для подписи всех обновлений прошивки, поскольку публичная половина будет находиться на ПК.Вы также можете подписать обновление прошивки с помощью ключа, который связан с ключом обновления Secure Firmware.
Может быть один ключ на ПК, например ПК, или один на модель, или один на продуктовую линейку. Если есть один ключ для каждого ПК, это будет означать, что необходимо будет сгенерировать миллионы уникальных пакетов обновлений.
Открытый ключ Secure Firmware Update (или его хэш для экономии места) будет храниться в каком-либо защищенном хранилище на платформе — обычно защищенной флэш-памяти (ПК) или одноразовых программируемых предохранителях (SOC).
Если хранится только хэш этого ключа (для экономии места), то обновление прошивки будет включать ключ, и на первом этапе процесса обновления будет проверяться соответствие открытого ключа в обновлении хешу, хранящемуся на платформе. .
Капсулы — это средство, с помощью которого ОС может передавать данные в среду UEFI при перезагрузке. Windows вызывает UEFI UpdateCapsule () для доставки обновлений прошивки системы и ПК. Во время загрузки перед вызовом ExitBootServices () Windows будет передавать все новые обновления прошивки, найденные в хранилище драйверов Windows, в UpdateCapsule ().Системная микропрограмма UEFI может использовать этот процесс для обновления микропрограммы системы и ПК.
Подробнее о реализации поддержки платформы обновления микропрограмм Windows UEFI см. В следующей документации: Платформа обновления микропрограмм Windows UEFI.
Капсулы обновления могут быть в памяти или на диске.Windows поддерживает обновления памяти.
1.3.6.1 Капсула (капсула в памяти)
Ниже приводится последовательность событий для работы капсулы обновлений в памяти.
- Капсула помещается в память приложением в ОС
- Событие почтового ящика установлено для информирования BIOS об ожидающем обновлении
- ПК перезагружается, проверяет образ капсулы, и обновление выполняется BIOS
1.3.7 Рабочий процесс типичного обновления прошивки
- Загрузите и установите драйвер микропрограммы.
- Перезагрузка.
- OS Loader обнаруживает и проверяет прошивку.
Загрузчик ОС- передает двоичный большой двоичный объект в UEFI.
- UEFI выполняет обновление прошивки (этот процесс принадлежит поставщику микросхем).
- Обнаружение загрузчика ОС успешно завершено.
- ОС завершает загрузку.
1.4 Базы данных подписи (Db и Dbx)
1.4.1 База данных разрешенных подписей (db)
Содержимое EFI
_IMAGE_SECURITY_DATABASEdb определяет, каким изображениям доверять при проверке загруженных изображений.База данных может содержать несколько сертификатов, ключей и хэшей для идентификации разрешенных изображений.Microsoft Windows Production PCA 2011 с хэшем сертификата SHA-1
58 0a 6f 4c c4 e4 b6 69 b9 eb dc 1b 2b 3e 08 7b 80 d0 67 8dдолжен быть включен в базу данных, чтобы разрешить Windows Загрузчик ОС для загрузки. Центр сертификации Windows можно загрузить отсюда: https://go.microsoft.com/fwlink/p/?linkid=321192.На ПК без Windows RT OEM должен рассмотреть возможность включения Microsoft Corporation UEFI CA 2011 с хэшем сертификата SHA-1
46 de f6 3b 5c e6 1c f8 ba 0d e2 e6 63 9c 10 19 d0 ed 14 f3.Подпись драйверов и приложений UEFI с помощью этого сертификата позволит драйверам и приложениям UEFI от сторонних производителей работать на ПК без дополнительных действий со стороны пользователя. UEFI CA можно скачать здесь: https://go.microsoft.com/fwlink/p/?linkid=321194.На ПК, отличных от Windows RT, OEM может также иметь дополнительные элементы в базе данных, чтобы разрешить использование других операционных систем или драйверов или приложений UEFI, одобренных OEM, но эти образы не должны каким-либо образом ставить под угрозу безопасность ПК.
1.4.2 DbDefault : поставщик платформы может предоставить набор записей по умолчанию для базы данных сигнатур в переменной dbDefault. Дополнительные сведения см. В разделе 27.5.3 спецификации UEFI.
1.4.3 База данных запрещенных подписей (dbx)
Содержимое
EFI_IMAGE_SIGNATURE_DATABASE1dbx должно быть проверено при проверке образов перед проверкой db, и любые совпадения должны препятствовать выполнению образа.База данных может содержать несколько сертификатов, ключей и хэшей для идентификации запрещенных изображений. В требованиях к сертификации оборудования Windows указано, что dbx должен присутствовать, поэтому любое фиктивное значение, такое как хэш SHA-256, равное0, может использоваться в качестве безопасного заполнителя до тех пор, пока Microsoft не начнет доставлять обновления dbx. Щелкните здесь, чтобы загрузить последний список отозванных UEFI от Microsoft.1.4.4 DbxDefault : поставщик платформы может предоставить набор записей по умолчанию для базы данных сигнатур в переменной dbxDefault.Дополнительные сведения см. В разделе 27.5.3 спецификации UEFI.
1.5 Ключи, необходимые для безопасной загрузки на всех ПК
Ключ / имя базы данных Переменная Владелец Банкноты PKpub
ПК
OEM
Только ПК — 1. Должен быть RSA 2048 или выше.
Microsoft Corporation KEK CA 2011
KEK
Microsoft
Позволяет обновлять db и dbx:
https: // go.microsoft.com/fwlink/p/?linkid=321185.
Microsoft Windows Production CA 2011
дб
Microsoft
Этот ЦС в базе данных сигнатур (db) позволяет Windows загружаться: https://go.microsoft.com/fwlink/?LinkId=321192.
База данных запрещенных подписей
DBX
Microsoft
Список известных плохих ключей, центров сертификации или образов от Microsoft
Ключ безопасного обновления прошивки
OEM
Рекомендуется, чтобы этот ключ отличался от PK
Таблица 1: Ключи / БД, необходимые для безопасной загрузки
2.Решения для управления ключами
Ниже приведены некоторые показатели, которые мы использовали для сравнения.
2.1 Используемые метрики
Следующие показатели помогут вам выбрать HSM-ПК в соответствии с требованиями спецификации UEFI 2.3.1 Errata C и вашими потребностями.
Связанные с инфраструктурой открытых ключей (PKI)
- Поддерживает ли он RSA 2048 или выше? — Спецификация UEFI 2.3.1 Errata C рекомендует использовать ключи RSA-2048 или выше.
- Есть ли у него возможность генерировать ключи и подписывать?
- Сколько ключей он может хранить? Хранит ли он ключи в HSM или на подключенном сервере?
- Метод аутентификации для получения ключа.Некоторые ПК поддерживают наличие нескольких объектов аутентификации для получения ключа.
Стоимость
- Какая цена? HSM может варьироваться в цене от 1500 до 70 000 долларов в зависимости от доступных функций.
Производственная среда
- Скорость работы в заводском цехе. Криптопроцессоры могут ускорить создание ключей и доступ к ним.
- Простота настройки, развертывания, обслуживания.
- Требуются навыки и обучение?
- Доступ к сети для резервного копирования и высокой доступности
Стандарты и соответствие
- Какой у него уровень соответствия FIPS? Он устойчив к взлому?
- Поддержка других стандартов, например, API шифрования MS.
- Отвечает ли он требованиям правительства и других ведомств?
Надежность и аварийное восстановление
Разрешает ли резервное копирование ключей?
Резервные копии могут храниться как на месте в безопасном месте, которое физически отличается от компьютера CA и HSM, так и / или вне офиса.
Обеспечивает ли это высокую доступность для аварийного восстановления?
2.2 Опции управления ключами
2.2.1 Аппаратный модуль безопасности (HSM)
Исходя из вышеперечисленных критериев, это, вероятно, наиболее подходящее и безопасное решение. Большинство модулей HSM соответствуют уровню 3 FIPS 140-2. Соответствие FIPS 140-2 уровню 3 строго касается аутентификации и требует, чтобы ключи не экспортировались или не импортировались из HSM.
Они поддерживают несколько способов хранения ключей. Они могут храниться либо локально в самом HSM, либо на сервере, подключенном к HSM. На сервере ключи зашифрованы и хранятся, что предпочтительнее для решений, требующих хранения большого количества ключей.
Политика безопасности криптографического модуля должна определять политику физической безопасности, включая механизмы физической безопасности, которые реализованы в криптографическом модуле, такие как пломбы с контролем вскрытия, замки, переключатели реакции на вмешательство и обнуления, а также сигналы тревоги. Он также позволяет указать действия, необходимые оператору (операторам) для обеспечения физической безопасности, такие как периодическая проверка пломб с функцией контроля вскрытия или проверка переключателей реакции на вмешательство и обнуления.
2.2.1.1 Сеть HSM
Это решение является лучшим в своем классе с точки зрения безопасности, соблюдения стандартов, генерации ключей, хранения и поиска. Большинство этих ПК поддерживают высокую доступность и имеют возможность резервного копирования ключей.
Стоимость этих продуктов может исчисляться десятками тысяч долларов в зависимости от дополнительных услуг, которые они предлагают.
2.2.1.2 Автономный HSM
Они отлично работают с автономными серверами. Можно использовать Microsoft CAPI и CNG или любой другой безопасный API, поддерживаемый HSM.Эти модули HSM имеют различные форм-факторы, поддерживающие шины USB, PCIe и PCMCIA.
Они опционально поддерживают резервное копирование ключей и высокую доступность.
2.2.2 Поставщики индивидуальных решений
Криптография с открытым ключомможет быть сложной задачей и потребовать понимания криптографических концепций, которые могут быть новыми. Существуют поставщики специализированных решений, которые могут помочь в обеспечении безопасной загрузки в производственной среде.
Существуют различные индивидуальные решения, предлагаемые поставщиками BIOS, компаниями HSM и консалтинговыми компаниями по PKI, чтобы заставить безопасную загрузку PKI работать в производственной среде.
Некоторые из провайдеров перечислены ниже:
2.2.3 Доверенный платформенный модуль (TPM)
Trusted Platform Module (TPM) — это аппаратный чип на материнской плате, в котором хранятся криптографические ключи, используемые для шифрования. Многие компьютеры включают TPM, но если на ПК его нет, добавить его невозможно. После включения Trusted Platform Module может помочь защитить продукты полного шифрования диска, такие как возможности Microsoft BitLocker. Он держит жесткие диски заблокированными или запечатанными до тех пор, пока компьютер не завершит процесс проверки или аутентификации системы.
TPM может создавать, хранить и защищать ключи, используемые в процессе шифрования и дешифрования.
Недостатки TPM заключаются в том, что он может не иметь быстрых криптопроцессоров для ускорения обработки в производственной среде. Они также не подходят для хранения большого количества ключей. Резервное копирование, высокая доступность и соответствие стандартам FIPS 140-2 уровня 3 могут быть недоступны.
2.2.4 Смарт-карты
Смарт-карта может генерировать и хранить ключи.У них есть общие функции, поддерживаемые HSM, такие как аутентификация и защита от несанкционированного доступа, но они не включают в себя много места для хранения ключей или резервного копирования. Они требуют ручного вмешательства и могут не подходить для автоматизации и использования в производственной среде, поскольку производительность может быть низкой.
Недостатки смарт-карт аналогичны TPM. У них может не быть быстрых криптопроцессоров для ускорения обработки в производственной среде. Они также не подходят для хранения большого количества ключей. Резервное копирование, высокая доступность и соответствие стандартам FIPS 140-2 уровня 3 могут быть недоступны.
2.2.5 Сертификат расширенной валидации
СертификатыEV — это сертификаты с высоким уровнем надежности, закрытые ключи которых хранятся в аппаратных токенах. Это помогает установить более эффективные методы управления ключами. Сертификаты EV имеют те же недостатки, что и смарт-карты.
2.2.6 Программно-ориентированные подходы (НЕ РЕКОМЕНДУЕТСЯ)
Используйте криптографические API для управления ключами. Это может включать хранение ключа в контейнере ключей на зашифрованном жестком диске и, возможно, для дополнительной изолированности и безопасности использование виртуальной машины.
Эти решения не так безопасны, как использование HSM, и раскрывают более высокий вектор атаки.
2.2.6.1 Makecert (НЕ РЕКОМЕНДУЕТСЯ)
Makecert — это инструмент Microsoft, который можно использовать для генерации ключей следующим образом. Чтобы убедиться, что поверхность атаки сведена к минимуму, вам может понадобиться «воздушный зазор» ПК. Компьютер, на котором включен PKpriv, не должен подключаться к сети. Он должен находиться в безопасном месте и в идеале должен использовать хотя бы считыватель смарт-карт, если не настоящий HSM.
makecert -pe -ss MY - $ индивидуальный -n "CN = ваше имя здесь" -len 2048 -rДля получения дополнительной информации см. Средство создания сертификатов (Makecert.exe).
Это решение не рекомендуется.
2.3 Создание и хранение ключей HSM для ключей безопасной загрузки
2.3.1 Хранение закрытых ключей
Требуемое пространство для каждого ключа RSA-2048 составляет 2048 бит. Фактическое место хранения ключей зависит от выбранного решения.HSM — хороший способ хранения ключей.
Физическое расположение ПК в производственном цехе должно быть защищенной зоной с ограниченным доступом пользователей, например, в защищенном отсеке.
В зависимости от ваших требований эти ключи также могут храниться в другом географическом месте или иметь резервную копию в другом месте.
Требования к смене ключей для этих ключей могут варьироваться в зависимости от клиента (см. Приложение A, где приведены инструкции по смене ключей федерального центра сертификации мостов).
Это можно делать один раз в год.Вам может потребоваться доступ к этим ключам на срок до 30 лет (в зависимости от требований к смене ключей и т. Д.).
2.3.2 Получение закрытых ключей
Ключи могут потребоваться по многим причинам.
- Может потребоваться восстановить ПК, чтобы выпустить обновленный ПК из-за того, что он скомпрометирован, или для соблюдения постановлений правительства / других агентств.
- KEKpri будет использоваться для обновления db и dbx.
- Ключ безопасного обновления прошивки –pri будет использоваться для подписи новых обновлений.
2.3.3 Аутентификация
Согласно FIPS 140-2 аутентификация основана на уровне доступа.
Уровень 2
Уровень безопасности 2 требует, как минимум, аутентификации на основе ролей, при которой криптографический модуль аутентифицирует авторизацию оператора, чтобы взять на себя определенную роль и выполнить соответствующий набор услуг.
Уровень 3
Уровень безопасности 3 требует механизмов аутентификации на основе идентичности, повышая безопасность, обеспечиваемую механизмами аутентификации на основе ролей, указанными для Уровня безопасности 2.Криптографический модуль аутентифицирует личность оператора и проверяет, что идентифицированный оператор уполномочен принимать на себя определенную роль и выполнять соответствующий набор услуг.
ПК, такие как HSM, поддерживают уровень безопасности 3, который требует «k of m аутентификации» на основе идентификации. Это означает, что k объектам предоставляется доступ к HSM с помощью токена, но в данной точке должно присутствовать по крайней мере k из m токенов, чтобы аутентификация работала для получения доступа к закрытым ключам из HSM.
Например, у вас может быть 3 из 5 токенов, которые должны быть аутентифицированы для доступа к HSM. Эти члены могут быть сотрудниками службы безопасности, авторизатором транзакций и / или членами исполнительного руководства.
Токены HSM
У вас может быть политика на HSM, которая требует наличия токена:
Рекомендуется использовать комбинацию токена и пароля для каждого токена.
2.4 Безопасная загрузка и сторонняя подпись
2.4.1 Подпись драйвера UEFI
ДрайверыUEFI должны быть подписаны центром сертификации или иметь ключ в базе данных, как описано в другом месте документа, или иметь хэш образа драйвера, включенного в базу данных. Microsoft будет предоставлять службу подписи драйверов UEFI, аналогичную службе подписи драйверов WHQL, с использованием Microsoft Corporation UEFI CA 2011 . Любые драйверы, подписанные этим, будут без проблем работать на любых компьютерах, которые включают Microsoft UEFI CA. OEM также может подписать доверенные драйверы и включить OEM CA в базу данных или включить хэши драйверов в базу данных.Во всех случаях драйвер UEFI (дополнительное ПЗУ) не будет выполняться, если он не является доверенным в базе данных.
Любые драйверы, включенные в образ микропрограммы системы, не нуждаются в повторной проверке. Наличие части общего образа системы обеспечивает достаточную уверенность в том, что драйвер надежен на ПК.
Microsoft сделала это доступным для всех, кто хочет подписать драйверы UEFI. Этот сертификат является частью тестов Windows HCK Secure Boot. Следите за [этим блогом] ((https://blogs.msdn.microsoft.com / windows_hardware_certification / 2013/12/03 / microsoft-uefi-ca-signed-policy-updates /), чтобы узнать больше о политике подписи UEFI CA и обновлениях.
2.4.2 Загрузчики загрузчика
Сертификат подписи драйвера Microsoft UEFI может использоваться для подписи других ОС. Например, загрузчик Fedora Linux будет им подписан.
Это решение не требует добавления дополнительных сертификатов к ключу Db. Помимо рентабельности, его можно использовать для любого дистрибутива Linux.Это решение будет работать на любом оборудовании, поддерживающем Windows, поэтому оно полезно для широкого спектра оборудования.
UEFI-CA можно загрузить отсюда: https://go.microsoft.com/fwlink/p/?LinkID=321194. По следующим ссылкам можно найти дополнительную информацию о подписании и отправке Windows HCK UEFI:
3. Резюме и ресурсы
Этот раздел предназначен для обобщения вышеуказанных разделов и демонстрации пошагового подхода:
Создание безопасного центра сертификации или определение партнера для безопасного создания и хранения ключей
Если вы не используете стороннее решение:
Установите и настройте программное обеспечение HSM на сервере HSM. Обратитесь к справочному руководству HSM для получения инструкций по установке. Сервер будет подключен к автономному или сетевому HSM.
Для получения информации о конфигурации HSM см. Разделы 2.2.1, 2.3 и Приложение C.
Большинство модулей HSM соответствуют требованиям FIPS 140-2 уровня 2 и 3. Настройте HSM для соответствия уровню 2 или 3. Соответствие уровню 3 предъявляет более строгие требования к аутентификации и доступу с ключами и, следовательно, является более безопасным. Рекомендуется уровень 3.
Настройте HSM для обеспечения высокой доступности, резервного копирования и аутентификации. Обратитесь к справочному руководству по HSM.
Следуйте инструкциям поставщика HSM по настройке HSM для обеспечения высокой доступности и резервного копирования.
Кроме того, сетевые HSM обычно имеют несколько сетевых портов для разделения трафика; позволяя серверу обмениваться данными с сетевыми HSM в сети, отдельной от обычной производственной сети.
После того, как члены группы, входящие в группу безопасности, были идентифицированы и им были присвоены жетоны. Вам потребуется настроить аппаратное обеспечение HSM для аутентификации k-of-m.
Ключи безопасной загрузки и предварительное создание сертификата. См. Разделы с 1.3 по 1.5
Используйте API-интерфейсы HSM, чтобы предварительно сгенерировать (сгенерировать) PK, ключ обновления микропрограммы и сертификаты.
Требуется — PK (рекомендуется 1 для каждой модели), ключ обновления микропрограммы (рекомендуется 1 для каждой модели), Microsoft KEK, Db, Dbx ПРИМЕЧАНИЕ: Microsoft KEK, db и dbx не обязательно должны создаваться OEM и упоминаются для Необязательно — OEM / сторонние KEK db, dbx и любые другие ключи, которые войдут в OEM Db.
Примените образ Windows к ПК.
Установите Microsoft db и dbx . См. Раздел 1.3.6 и Приложение B — API безопасной загрузки.
Установите Microsoft Windows Production PCA 2011 в db.
Установите пустой dbx, если Microsoft его не предоставляет. Windows автоматически обновит DBX до последней версии DBX через Центр обновления Windows при первой перезагрузке.
Примечание
Используйте командлеты PowerShell, которые являются частью тестов Windows HCK, или используйте методы, предоставленные поставщиком BIOS.
Установите Microsoft KEK . См. Раздел 1.3.3.
Установить Microsoft KEK в базу данных UEFI KEK
Осторожно
Используйте командлеты PowerShell, которые являются частью тестов Windows HCK, или используйте методы, предоставленные поставщиком BIOS.
Необязательный шаг — компоненты безопасной загрузки OEM / сторонних производителей . См. Разделы 1.3.4 и 1.4.
Определите, нужно ли вам создавать OEM / сторонние KEK, db и dbx.
Подписать OEM / сторонние db и dbx с OEM / сторонним KEK (сгенерированным ранее) с помощью HSM API.
Установите OEM / сторонние KEK, db и dbx.
Подпись драйвера UEFI — см. Раздел 2.4.
Если поддерживаются карты расширения или другие драйверы / приложения / загрузчики UEFI, установите Microsoft Corporation UEFI CA 2011 в базу данных UEFI.
Ключ обновления микропрограммы безопасной загрузки — см. Раздел 1.3.5.
Только для ПК без Windows RT: установите открытый ключ безопасного обновления микропрограммы или его хэш для экономии места.
Только на SoC может потребоваться что-то другое, например, записать защищенный ключ обновления прошивки: общедоступный или его хэш.
Включение безопасной загрузки . См. Приложение B — API безопасной загрузки.
Установите OEM / ODM PKpub (сертификат предпочтительнее, но ключ допустим) в UEFI PK.
Зарегистрируйте ПК с помощью API безопасной загрузки. Теперь компьютер должен быть включен для безопасной загрузки.
Примечание
Если вы устанавливаете PK в конце, MS KEK, db, dbx не нужно подписывать — SignerInfo не требуется. Это ярлык.
Тестирование безопасной загрузки : Выполните все проприетарные тесты и тесты Windows HCK в соответствии с инструкциями. См. Приложение B — API безопасной загрузки.
Судовая платформа : PKpriv, скорее всего, больше никогда не будет использоваться, сохраните его.
Обслуживание : будущие обновления микропрограмм надежно подписываются с помощью «закрытого» ключа безопасного обновления микропрограмм с использованием службы подписи.
3.1 Ресурсы
Официальный документ по стратегиям безопасности— https://go.microsoft.com/fwlink/p/?linkid=321288
Отправка Windows HCK — https://go.microsoft.com/fwlink/p/? Linkid = 321287
Приложение A — Контрольный список PKI безопасной загрузки для производства
Ниже приведен общий контрольный список, в котором перечислены шаги, необходимые для включения безопасной загрузки на компьютерах, отличных от Windows RT.
Настройка безопасной загрузки
Определите стратегию безопасности (идентифицируйте угрозы, определите упреждающую и реактивную стратегии) в соответствии с техническим документом в разделе 4.
Определите группу безопасности в соответствии с информационным документом в разделе 4.
Создайте безопасный центр сертификации или определите партнера (рекомендуемое решение) для безопасного создания и хранения ключей.
Определите политику частоты смены ключей. Это может зависеть от того, есть ли у вас какие-либо особые требования клиентов, например, правительства или другие агентства.
Имейте план действий в чрезвычайных ситуациях на случай взлома ключа безопасной загрузки.
Определите, сколько PK и других ключей вы будете генерировать согласно разделам 1.3.3 и 1.5.
Это будет основано на клиентской базе, решении для хранения ключей и безопасности ПК.
Вы можете пропустить шаги 7-8, если вы используете рекомендованное решение с использованием стороннего производителя для управления ключами.
Приобретите сервер и оборудование для управления ключами.- сетевой или автономный HSM согласно разделу 2.2.1. Подумайте, понадобится ли вам один или несколько HSM для обеспечения высокой доступности, и определите стратегию резервного копирования ключей.
Определите как минимум 3-4 члена группы, у которых будет токен аутентификации для аутентификации в HSM.
Используйте HSM или стороннее устройство для предварительного создания ключей и сертификатов, связанных с безопасной загрузкой. Ключи будут зависеть от типа ПК: SoC, Windows RT или не-Windows RT. Для получения дополнительной информации см. Разделы с 1.3 по 1.5.
Залейте прошивку соответствующими ключами.
Зарегистрируйте ключ платформы безопасной загрузки, чтобы включить безопасную загрузку. См. Приложение B для более подробной информации.
Выполните все проприетарные тесты и тесты безопасной загрузки HCK в соответствии с инструкциями. См. Приложение B для более подробной информации.
Отправьте ПК. PKpriv, скорее всего, больше никогда не будет использоваться, держите его в безопасности.
Обслуживание (обновление прошивки)
Вам может потребоваться обновить микропрограммное обеспечение по нескольким причинам, например, для обновления компонента UEFI или исправления компрометации ключа безопасной загрузки или периодической смены ключей ключей безопасной загрузки.
Для получения дополнительной информации см. Раздел 1.3.5 и Раздел 1.3.6.
Приложение B. API безопасной загрузки
API безопасной загрузки
Следующие API связаны с UEFI / Secure Boot:
GetFirmwareEnvironmentVariableEx: извлекает значение указанной переменной среды микропрограммы.
SetFirmwareEnvironmentVariableEx: устанавливает значение указанной переменной среды микропрограммы.
GetFirmwareType: извлекает тип прошивки.
Установка ПК
Используйте командлет Set-SecureBootUEFI, чтобы включить безопасную загрузку. После того, как ваш код установит PK, принудительное применение безопасной загрузки системой не вступит в силу до следующей перезагрузки. Перед перезагрузкой ваш код мог вызвать GetFirmwareEnvironmentVariableEx () или командлет PowerShell: Get-SecureBootUEFI для подтверждения содержимого баз данных безопасной загрузки.
Проверка
Вы можете использовать Msinfo32.exe или PowerShell для проверки состояния переменной безопасной загрузки. Интерфейса WMI нет. Вы также можете проверить, попросив кого-нибудь вставить загрузочный USB-накопитель с неверной подписью (например, из теста Windows HCK Secure Boot Manual Logo Test) и убедиться, что он не загружается.
Командлеты Powershell для безопасной загрузки
Confirm-SecureBootUEFI : включена ли безопасная загрузка UEFI, верна она или нет?
SetupMode == 0 && SecureBoot == 1
Set-SecureBootUEFI : установка или добавление аутентифицированных переменных SecureBoot UEFI
Get-SecureBootUEFI : получить аутентифицированные значения переменных SecureBoot UEFI
Format-SecureBootUEFI : Создает EFI_SIGNATURE_LISTs и EFI_VARIABLE_AUTHENTICATION_2 сериализации
Windows HCK и инструкции по безопасной загрузке
Следующие шаги применимы к системным тестам и тестам ПК с драйверами, не относящимися к классу.
Отключить защиту безопасной загрузки.
Введите конфигурацию BIOS и отключите безопасную загрузку.
Установите программное обеспечение клиента HCK.
Запустить все тесты Windows HCK, кроме следующего:
- Тестирование TPM BitLocker и пароля восстановления с помощью PCR [7]
- BitLocker TPM и тесты пароля восстановления для компьютеров ARM с безопасной загрузкой
- Тест логотипа безопасной загрузки
- Безопасная загрузка, ручная проверка логотипа
Введите конфигурацию BIOS, включите безопасную загрузку и восстановите безопасную загрузку до конфигурации по умолчанию.
Запустите следующие тесты BitLocker и безопасной загрузки:
- Тестирование TPM BitLocker и пароля восстановления с помощью PCR [7]
- BitLocker TPM и тесты пароля восстановления для компьютеров ARM с безопасной загрузкой
- Тест логотипа безопасной загрузки (автоматизированный)
Войдите в конфигурацию BIOS и очистите конфигурацию безопасной загрузки. Это вернет ПК в режим настройки, удалив PK и другие ключи.
Примечание
Поддержка очистки требуется для компьютеров x86 / x64.
Запустите проверку логотипа вручную при безопасной загрузке.
Примечание
Для безопасной загрузкитребуются подписанные Windows HCK или драйверы VeriSign на ПК, отличных от Windows RT
Тест логотипа безопасной загрузки Windows HCK (автоматизированный)
Этот тест проверяет правильность заводской конфигурации безопасной загрузки. Сюда входят:
- Безопасная загрузка включена.
- ПК не является известным, испытательный ПК.
- KEK содержит продукцию Microsoft KEK.
- db содержит рабочий центр сертификации Windows.
- dbx присутствует.
- Создается / удаляется множество переменных размером 1 КБ.
- Создана / удалена переменная размером 32 КБ.
Макет папки ручного тестирования Windows HCK Secure Boot для ручного тестирования
Схема тестовой папки с логотипом вручную безопасной загрузки Windows HCK описана ниже:
Папка "\ Test"имеет следующее:
- Производственные и сервисные испытания
- Программно включить безопасную загрузку в тестовой конфигурации
- Сервисные испытания
- Добавить сертификат в базу данных, проверить функцию
- Добавить хэш в dbx, проверить функцию
- Добавить сертификат в dbx, проверить функцию
- Добавить 600+ хэшей в dbx, проверить размер
- Программное изменение PK
Папка "\ Generate"содержит сценарии, которые показывают следующее:
Как создавались сертификаты испытаний
Тестовые сертификаты и закрытые ключи включены
Как были созданы все тесты
Превращение сертификатов и хэшей в подписанные пакеты
Можете запустить сами, подставьте свои сертификаты
Папка "\ certs"содержит все сертификаты, необходимые для загрузки Windows:Примечание
Не используйте методологию, используемую в
"ManualTests \ generate \ TestCerts"для создания ключей и сертификатов.Это предназначено только для целей тестирования Windows HCK. Он использует ключи, которые хранятся на диске, что очень небезопасно и не рекомендуется. Это не предназначено для использования в производственной среде.
Папка "ManualTests \ example \ OutOfBox"содержит сценарии, которые можно использовать для установки безопасной загрузки на производственные ПК.
«ManualTests \ generate \ tests \ subcreate_outofbox_example.ps1»демонстрирует, как эти примеры были сгенерированы и имеют разделы «TODO», когда партнер может заменить свой PK и другие метаданные.
Windows HCK UEFI подписание и отправка
Дополнительная информация по следующим ссылкам:
Приложение C. Сопоставление сертификатов сертификатов Федерального центра сертификации мостов
Элементарный
Этот уровень обеспечивает самую низкую степень уверенности в отношении личности человека. Одна из основных функций этого уровня — обеспечить целостность подписываемой информации.Этот уровень актуален для сред, в которых риск злонамеренных действий считается низким. Он не подходит для транзакций, требующих аутентификации, и, как правило, недостаточен для транзакций, требующих конфиденциальности, но может использоваться для последних, когда недоступны сертификаты с более высоким уровнем гарантии.
Базовый
Этот уровень обеспечивает базовый уровень уверенности, относящийся к средам, в которых существуют риски и последствия компрометации данных, но они не считаются имеющими большое значение.Это может включать доступ к частной информации, где вероятность злонамеренного доступа невысока. На этом уровне безопасности предполагается, что пользователи не могут быть злоумышленниками.
Среднее
Этот уровень актуален для сред, в которых риски и последствия компрометации данных умеренные. Это может включать транзакции, имеющие значительную денежную ценность или риск мошенничества, или связанные с доступом к частной информации, когда вероятность злонамеренного доступа высока.
 ',' x ']
',' x ']  rcParams.update (mpl.rcParamsDefault) # сбросить стиль ggplot # Вызвать функцию двухплота только для первых 2 ПК
rcParams.update (mpl.rcParamsDefault) # сбросить стиль ggplot # Вызвать функцию двухплота только для первых 2 ПК 
 Иногда это называют выполнением PCA на корреляционной матрице.Вы почти всегда выбрали бы этот подход, если бы ваши переменные измерялись с использованием разных единиц.
Иногда это называют выполнением PCA на корреляционной матрице.Вы почти всегда выбрали бы этот подход, если бы ваши переменные измерялись с использованием разных единиц.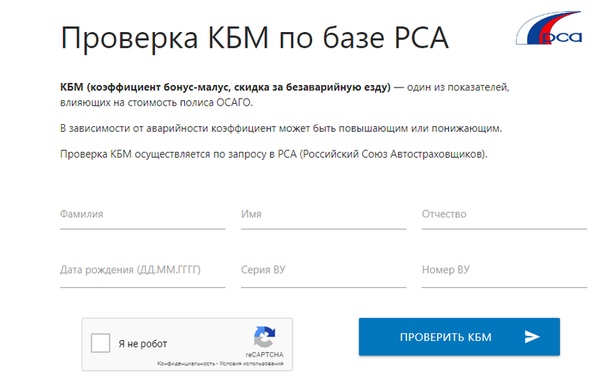 Поскольку переменные не масштабируются, переменные с большими стандартными отклонениями, чем другие, будут в первую очередь определять первые главные компоненты.Математически
Поскольку переменные не масштабируются, переменные с большими стандартными отклонениями, чем другие, будут в первую очередь определять первые главные компоненты.Математически Вот как работает параллельный анализ:
Вот как работает параллельный анализ: Если собственное значение из входных данных больше, чем верхний процентиль из смоделированных данных, компонент выбирается, иначе компонент не выбран.
Если собственное значение из входных данных больше, чем верхний процентиль из смоделированных данных, компонент выбирается, иначе компонент не выбран.
 Как бы мы ни хотели строить наши модели, не сталкиваясь со сложностями PCA, мы не сможем долго оставаться в стороне от него. Прелесть PCA заключается в его полезности.
Как бы мы ни хотели строить наши модели, не сталкиваясь со сложностями PCA, мы не сможем долго оставаться в стороне от него. Прелесть PCA заключается в его полезности. 8 FM (да! Станция, которая транслирует песни о любви …! 🙂 Итак, теперь, когда мы настроимся на FM на частоте 104,8, мы можем получить радиостанцию по нашему выбору. Кроме того, если вы заметили, настраиваемся ли мы FM на чуть более высокой частоте, скажем 105 или на более низкой частоте 104,5, мы все еще можем слышать радиостанцию. Однако что-то происходит, когда мы отходим от частоты 104,8. Позвольте мне показать это диаметрально.
8 FM (да! Станция, которая транслирует песни о любви …! 🙂 Итак, теперь, когда мы настроимся на FM на частоте 104,8, мы можем получить радиостанцию по нашему выбору. Кроме того, если вы заметили, настраиваемся ли мы FM на чуть более высокой частоте, скажем 105 или на более низкой частоте 104,5, мы все еще можем слышать радиостанцию. Однако что-то происходит, когда мы отходим от частоты 104,8. Позвольте мне показать это диаметрально. В нашем примере частоты — это та информация, которая нам нужна. Это также известно как отношение сигнал / шум.
В нашем примере частоты — это та информация, которая нам нужна. Это также известно как отношение сигнал / шум. При просмотре данных с точки зрения x 1 тогда данные, представленные в другом измерении, которое является разбросом или вертикальным подъемом в точках данных, представляют собой только шум для x 1 причина x 1 не может объясните эту вариацию.Точно так же вертикальный подъем в точках данных также является шумом с точки зрения x 2 , поскольку x 2 также не может объяснить этот разброс.
При просмотре данных с точки зрения x 1 тогда данные, представленные в другом измерении, которое является разбросом или вертикальным подъемом в точках данных, представляют собой только шум для x 1 причина x 1 не может объясните эту вариацию.Точно так же вертикальный подъем в точках данных также является шумом с точки зрения x 2 , поскольку x 2 также не может объяснить этот разброс.
 Y сильно зависит от X 1 и X 2 соответственно. Это предположение о независимости X 1 и X 2 друг от друга в действительности часто нарушается.
Y сильно зависит от X 1 и X 2 соответственно. Это предположение о независимости X 1 и X 2 друг от друга в действительности часто нарушается.
 Это друг с другом зафиксировано в модели до сих пор, а ковариация
Это друг с другом зафиксировано в модели до сих пор, а ковариация
 Это называется центрированием.
Это называется центрированием.

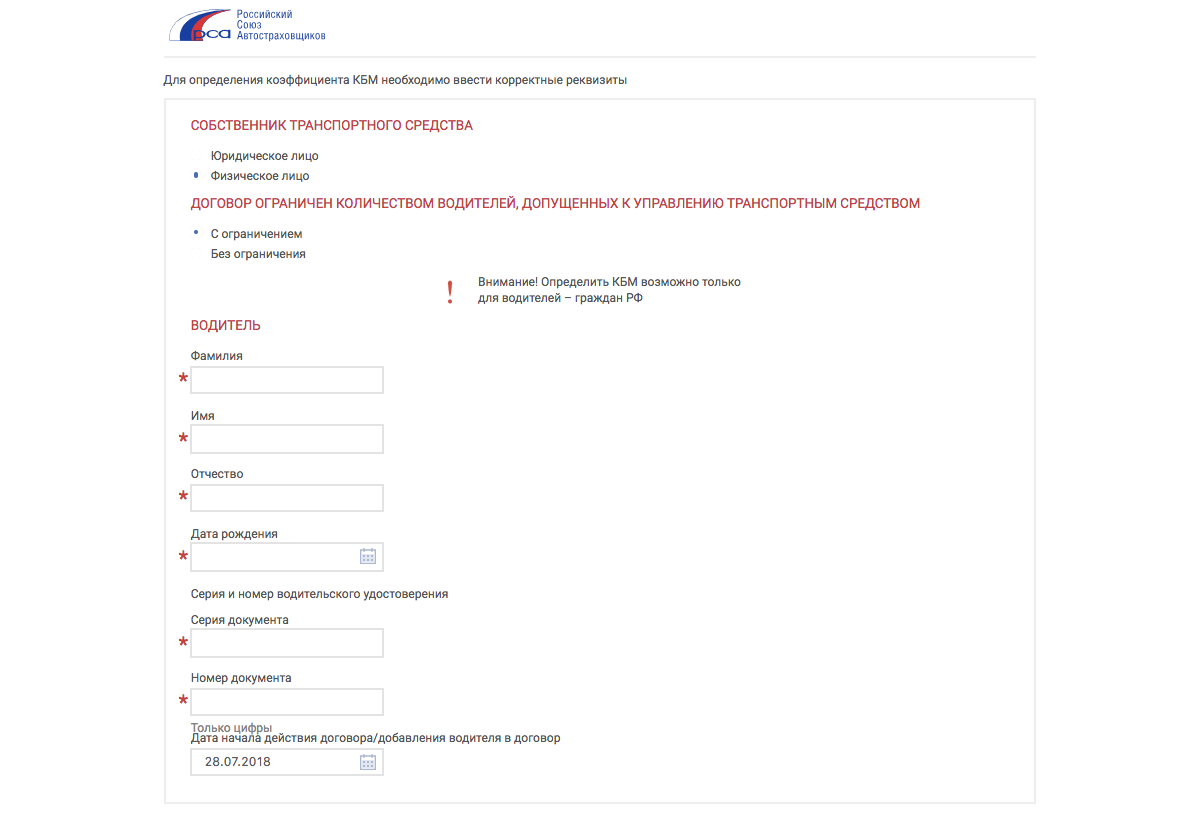 Ковариационная матрица — это не что иное, как числовая форма парного графика, которую мы получаем из sns.pairplot ().
Ковариационная матрица — это не что иное, как числовая форма парного графика, которую мы получаем из sns.pairplot (). Мы вычли средние значения из соответствующих xis по каждому из измерений i.е. преобразовали все измерения в их соответствующие Z-баллы, и это получение Z-показателей центрирует наши данные.
Мы вычли средние значения из соответствующих xis по каждому из измерений i.е. преобразовали все измерения в их соответствующие Z-баллы, и это получение Z-показателей центрирует наши данные. Это направления в исходном математическом пространстве, где фиксируется максимальный спред.Распространение — это сигнал или информационное содержание.
Это направления в исходном математическом пространстве, где фиксируется максимальный спред.Распространение — это сигнал или информационное содержание.
 Проще говоря, это означает, что мы разбиваем или разлагаем большее значение (то есть сингулярное значение) на меньшие значения. Что касается нашего контекста, мы разделили нашу ковариационную матрицу (большее сингулярное значение), которая была получена после масштабирования независимых переменных, на два выхода над собственными векторами (на меньшие значения) и получили их соответствующие собственные значения.
Проще говоря, это означает, что мы разбиваем или разлагаем большее значение (то есть сингулярное значение) на меньшие значения. Что касается нашего контекста, мы разделили нашу ковариационную матрицу (большее сингулярное значение), которая была получена после масштабирования независимых переменных, на два выхода над собственными векторами (на меньшие значения) и получили их соответствующие собственные значения. Короче говоря, S — это диагональная матрица с положительными значениями, которая называется сингулярной матрицей.
Короче говоря, S — это диагональная матрица с положительными значениями, которая называется сингулярной матрицей.

 Мы можем удалить любое из измерений, скажем, если мы удалим переменную X 2 , тогда мы потеряем информацию, поскольку сигнал, доступный в X 2 , отсутствует в переменной X 1 и наоборот. наоборот, если мы решим сохранить X 2 и отбросить переменную X 1 , то снова произойдет некоторая потеря информации, поскольку X 2 не будет содержать информацию, представленную в переменной X 1 .
Мы можем удалить любое из измерений, скажем, если мы удалим переменную X 2 , тогда мы потеряем информацию, поскольку сигнал, доступный в X 2 , отсутствует в переменной X 1 и наоборот. наоборот, если мы решим сохранить X 2 и отбросить переменную X 1 , то снова произойдет некоторая потеря информации, поскольку X 2 не будет содержать информацию, представленную в переменной X 1 . Затем мы можем отбросить исходные размеры X 1 и X 2 и построить нашу модель, используя только эти основные компоненты PC1 и PC2. Причина, по которой мы можем построить модель только с использованием компонентов, заключается в том, что, как мы видели, между компонентами нет ковариации, т.е. недиагональное информационное содержание равно нулю в новом математическом пространстве (хотя на самом деле ковариация близка к нулю) , а значит, поглощает всю информацию.
Затем мы можем отбросить исходные размеры X 1 и X 2 и построить нашу модель, используя только эти основные компоненты PC1 и PC2. Причина, по которой мы можем построить модель только с использованием компонентов, заключается в том, что, как мы видели, между компонентами нет ковариации, т.е. недиагональное информационное содержание равно нулю в новом математическом пространстве (хотя на самом деле ковариация близка к нулю) , а значит, поглощает всю информацию. е. собственные векторы) вместе с соответствующими собственными значениями в порядке убывания и составьте сводный график, как показано ниже.
е. собственные векторы) вместе с соответствующими собственными значениями в порядке убывания и составьте сводный график, как показано ниже.
 Не зависят друг от друга, и корреляция между этими производными характеристиками (ПК1….PC10) равны нулю. Следовательно, ПК являются функциями Xs.
Не зависят друг от друга, и корреляция между этими производными характеристиками (ПК1….PC10) равны нулю. Следовательно, ПК являются функциями Xs. Z_X10, и на втором этапе мы получаем корреляционную матрицу этих значений Z-оценок, которая представляет собой не что иное, как является квадратной матрицей, и мы видели выше, что любую матрицу можно разложить с помощью разложения по сингулярным числам.
Z_X10, и на втором этапе мы получаем корреляционную матрицу этих значений Z-оценок, которая представляет собой не что иное, как является квадратной матрицей, и мы видели выше, что любую матрицу можно разложить с помощью разложения по сингулярным числам. Кроме того, к настоящему времени известно, что каждый из ПК или основных компонентов имеет свои связанные собственные значения, которые представляют собой дисперсию или разброс, объясняющий информационный контент, присутствующий в этом измерении.
Кроме того, к настоящему времени известно, что каждый из ПК или основных компонентов имеет свои связанные собственные значения, которые представляют собой дисперсию или разброс, объясняющий информационный контент, присутствующий в этом измерении.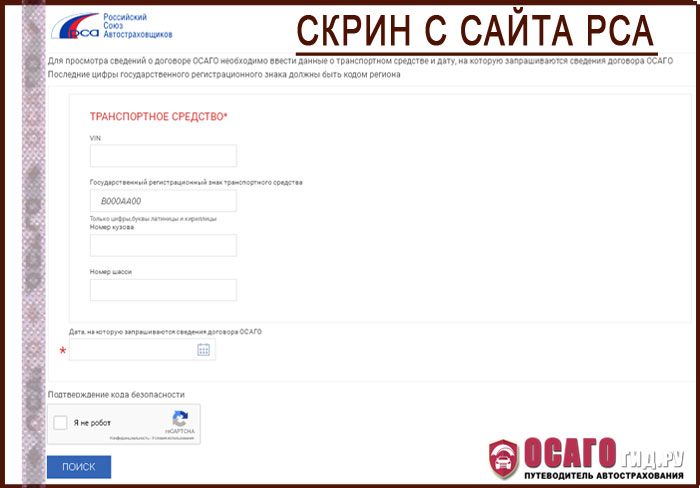

 25
25 Анализируя приведенную выше таблицу, мы видим:
Анализируя приведенную выше таблицу, мы видим: Основываясь на вкладе переменных, у нас есть три компонента из начальных пяти основных компонентов.
Основываясь на вкладе переменных, у нас есть три компонента из начальных пяти основных компонентов.



 Оба
Оба  Форматы ответов PCA для вывода и
Образцы записных книжек PCA.
Форматы ответов PCA для вывода и
Образцы записных книжек PCA.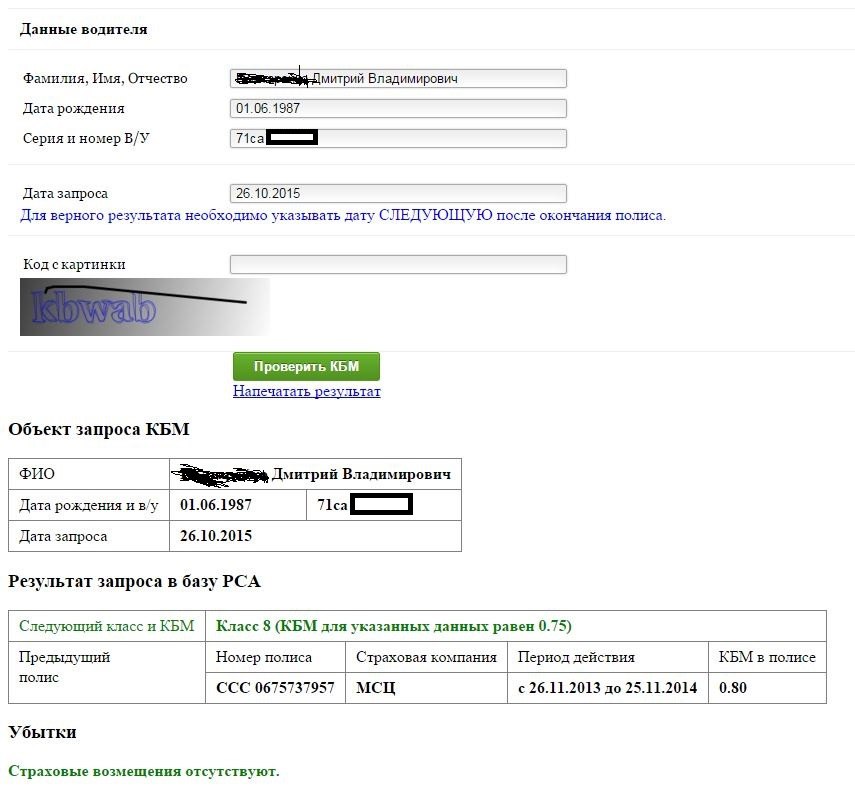 алгоритм анализа изображений рукописных цифр от нуля до девяти в MNIST
набор данных, см. Введение в PCA с MNIST.Инструкции по созданию и
доступ к экземплярам записной книжки Jupyter, которые можно использовать для запуска примера в SageMaker,
см. Использование экземпляров записных книжек Amazon SageMaker. После того, как вы создали экземпляр записной книжки и
открыл его, выберите вкладку SageMaker Примеры , чтобы увидеть
список всех образцов SageMaker. Тематический пример моделирования записных книжек с использованием
НТМ
алгоритмы находятся в разделе Introduction to Amazon.
алгоритмы раздела.Чтобы открыть записную книжку, щелкните вкладку Использовать и выберите Создать.
алгоритм анализа изображений рукописных цифр от нуля до девяти в MNIST
набор данных, см. Введение в PCA с MNIST.Инструкции по созданию и
доступ к экземплярам записной книжки Jupyter, которые можно использовать для запуска примера в SageMaker,
см. Использование экземпляров записных книжек Amazon SageMaker. После того, как вы создали экземпляр записной книжки и
открыл его, выберите вкладку SageMaker Примеры , чтобы увидеть
список всех образцов SageMaker. Тематический пример моделирования записных книжек с использованием
НТМ
алгоритмы находятся в разделе Introduction to Amazon.
алгоритмы раздела.Чтобы открыть записную книжку, щелкните вкладку Использовать и выберите Создать. копия .
копия .

 В качестве отраслевого стандарта Secure Boot определяет, как микропрограммное обеспечение платформы управляет сертификатами, аутентифицирует микропрограммное обеспечение и как операционная система взаимодействует с этим процессом.
В качестве отраслевого стандарта Secure Boot определяет, как микропрограммное обеспечение платформы управляет сертификатами, аутентифицирует микропрограммное обеспечение и как операционная система взаимодействует с этим процессом.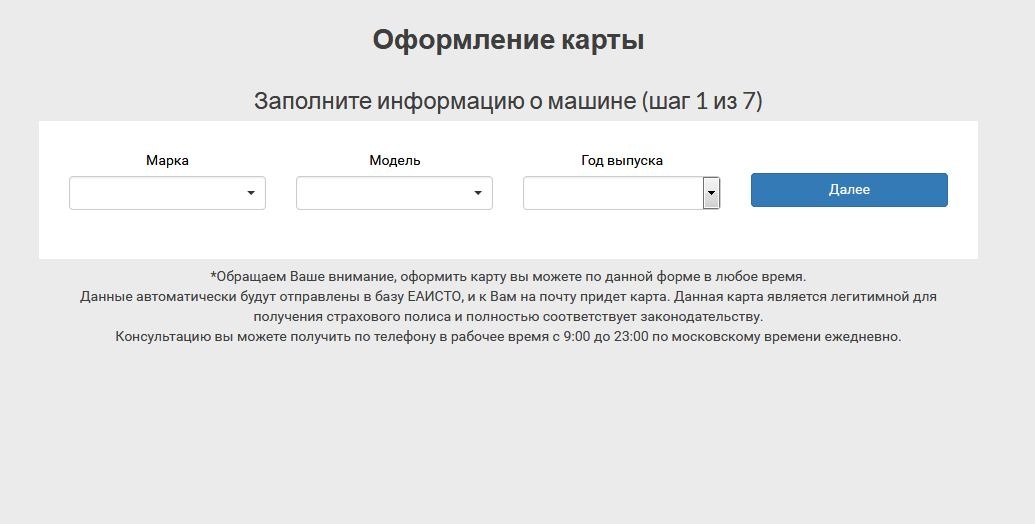

 1 Инфраструктура открытых ключей (PKI) и безопасная загрузка
1 Инфраструктура открытых ключей (PKI) и безопасная загрузка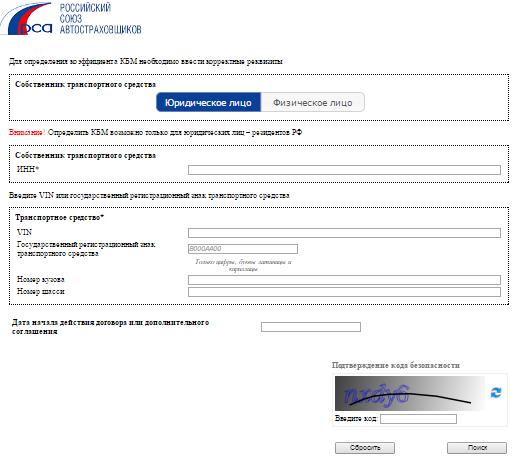 Если для шифрования информации используется один ключ, то только соответствующий ключ может расшифровать эту информацию. Для безопасной загрузки закрытый ключ используется для цифровой подписи кода, а открытый ключ используется для проверки подписи на этом коде, чтобы подтвердить его подлинность. Если закрытый ключ скомпрометирован, то системы с соответствующими открытыми ключами больше не защищены.Это может привести к атакам на загрузочный комплект и нанесет ущерб репутации организации, ответственной за обеспечение безопасности закрытого ключа.
Если для шифрования информации используется один ключ, то только соответствующий ключ может расшифровать эту информацию. Для безопасной загрузки закрытый ключ используется для цифровой подписи кода, а открытый ключ используется для проверки подписи на этом коде, чтобы подтвердить его подлинность. Если закрытый ключ скомпрометирован, то системы с соответствующими открытыми ключами больше не защищены.Это может привести к атакам на загрузочный комплект и нанесет ущерб репутации организации, ответственной за обеспечение безопасности закрытого ключа. Сертификаты корневого центра сертификации (CA) попадают в эту категорию.
Сертификаты корневого центра сертификации (CA) попадают в эту категорию.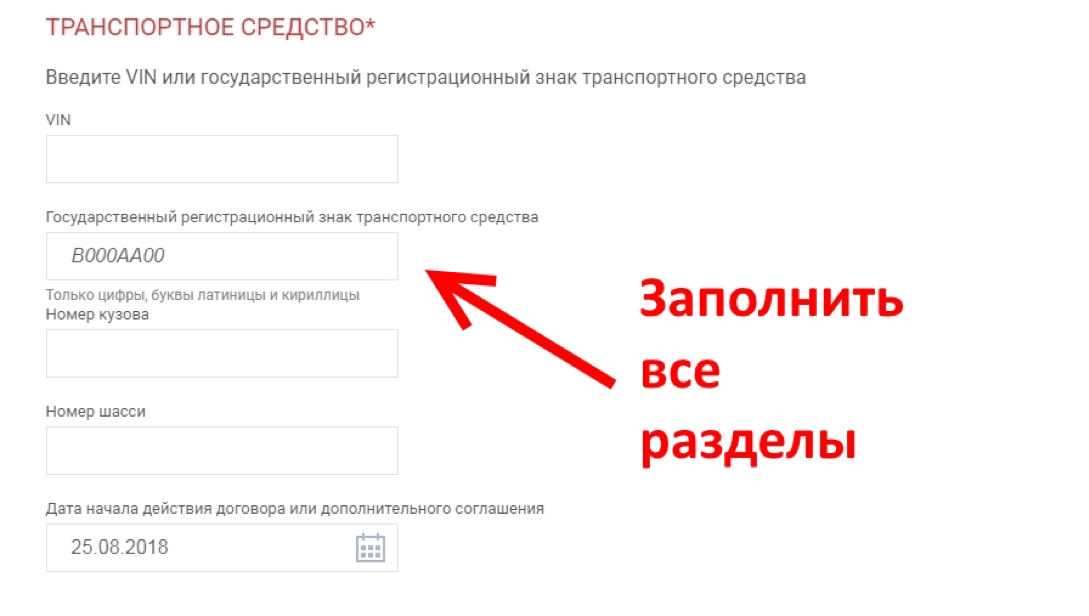
 Д. Обычно сертификаты используются для защиты сообщений в Интернете с использованием протокола TLS или протокола защищенных сокетов (SSL). Проверка подписанных данных с помощью сертификата позволяет получателю узнать источник данных и были ли они изменены при передаче.
Д. Обычно сертификаты используются для защиты сообщений в Интернете с использованием протокола TLS или протокола защищенных сокетов (SSL). Проверка подписанных данных с помощью сертификата позволяет получателю узнать источник данных и были ли они изменены при передаче. Это представляет собой цепочку из двух сертификатов. Проверка подлинности сертификата пользователя включает проверку его подписи, для чего требуется открытый ключ ЦС из его сертификата. Но прежде чем можно будет использовать открытый ключ ЦС, необходимо проверить прилагаемый сертификат ЦС.Поскольку сертификат ЦС является самоподписанным, для проверки сертификата используется открытый ключ ЦС.
Это представляет собой цепочку из двух сертификатов. Проверка подлинности сертификата пользователя включает проверку его подписи, для чего требуется открытый ключ ЦС из его сертификата. Но прежде чем можно будет использовать открытый ключ ЦС, необходимо проверить прилагаемый сертификат ЦС.Поскольку сертификат ЦС является самоподписанным, для проверки сертификата используется открытый ключ ЦС. Безопасность до UEFI и корень доверия рассматриваются не в процессе безопасной загрузки UEFI, а в публикациях Национального института стандартов и технологий (NIST) и Trusted Computing Group (TCG), упомянутых в этом документе.
Безопасность до UEFI и корень доверия рассматриваются не в процессе безопасной загрузки UEFI, а в публикациях Национального института стандартов и технологий (NIST) и Trusted Computing Group (TCG), упомянутых в этом документе.
 Возвращайтесь в режим настройки только в том случае, если это необходимо во время производства.
Возвращайтесь в режим настройки только в том случае, если это необходимо во время производства. Если PK имеет тип
Если PK имеет тип  В этом случае глобальная переменная Setup Mode также должна быть обновлена до 1.
В этом случае глобальная переменная Setup Mode также должна быть обновлена до 1. Это добавляет сложности сопоставления устройств с их соответствующими PK при распространении обновлений прошивки на устройства в будущем. Существует несколько различных решений HSM для управления большим количеством ключей в зависимости от поставщика HSM. Дополнительные сведения см. В разделе Создание ключа безопасной загрузки с помощью HSM.
Это добавляет сложности сопоставления устройств с их соответствующими PK при распространении обновлений прошивки на устройства в будущем. Существует несколько различных решений HSM для управления большим количеством ключей в зависимости от поставщика HSM. Дополнительные сведения см. В разделе Создание ключа безопасной загрузки с помощью HSM. Позже их можно было извлечь и использовать на сборочной линии. В главах 2 и 3 содержится более подробная информация.
Позже их можно было извлечь и использовать на сборочной линии. В главах 2 и 3 содержится более подробная информация.

 2.1. Если платформа находится в пользовательском режиме, база данных подписей должна быть подписана текущим PKpriv
2.1. Если платформа находится в пользовательском режиме, база данных подписей должна быть подписана текущим PKpriv
 Этот ключ должен иметь минимальную стойкость RSA-2048.Все обновления микропрограмм должны быть надежно подписаны производителем оборудования, его доверенным представителем, например ODM или IBV (независимый поставщик BIOS), или службой безопасной подписи.
Этот ключ должен иметь минимальную стойкость RSA-2048.Все обновления микропрограмм должны быть надежно подписаны производителем оборудования, его доверенным представителем, например ODM или IBV (независимый поставщик BIOS), или службой безопасной подписи.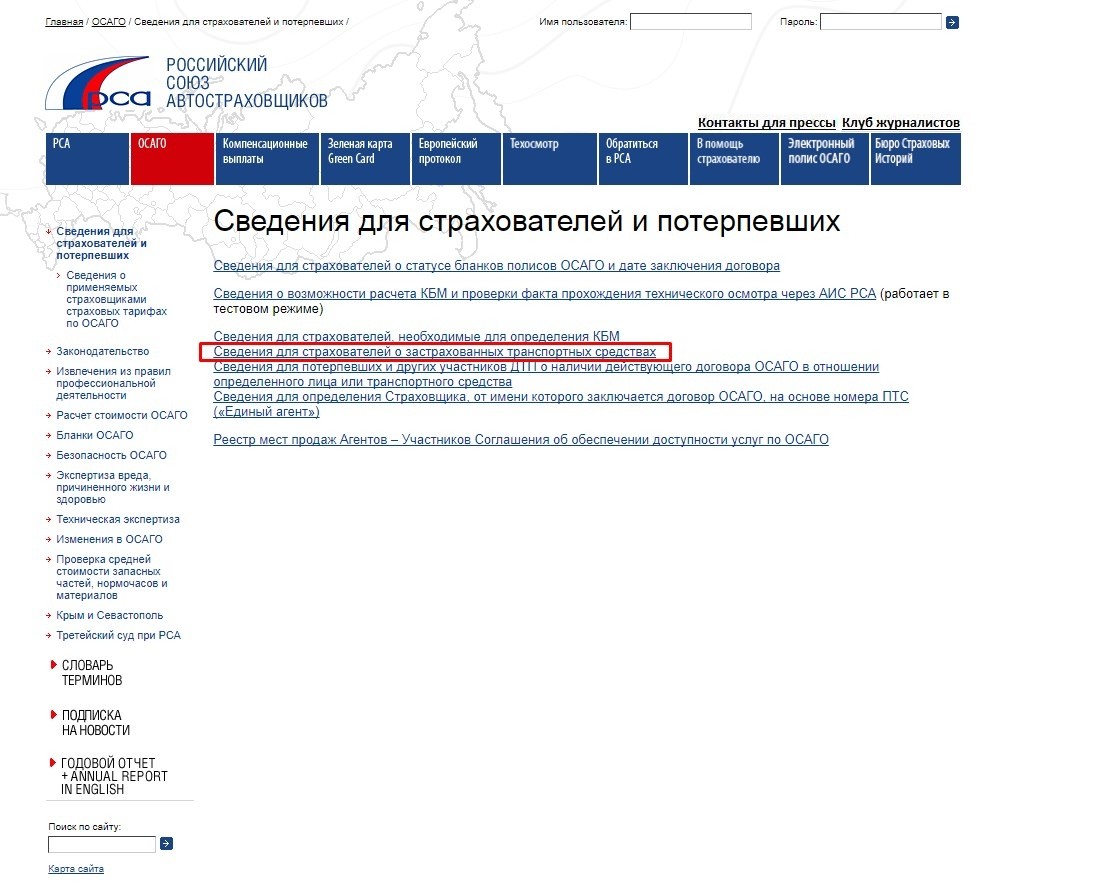 В зависимости от наличия ресурсов подумайте, какой метод подойдет вам. Наличие ключа для каждой модели или линейки продуктов — хороший компромисс.
В зависимости от наличия ресурсов подумайте, какой метод подойдет вам. Наличие ключа для каждой модели или линейки продуктов — хороший компромисс. Используя эту поддержку микропрограмм Windows, OEM-производитель может полагаться на один и тот же общий формат и процесс обновления микропрограмм как для системы, так и для микропрограмм ПК. Прошивка должна реализовывать таблицу ACPI ESRT для поддержки UEFI UpdateCapsule () для Windows.
Используя эту поддержку микропрограмм Windows, OEM-производитель может полагаться на один и тот же общий формат и процесс обновления микропрограмм как для системы, так и для микропрограмм ПК. Прошивка должна реализовывать таблицу ACPI ESRT для поддержки UEFI UpdateCapsule () для Windows.