Что делать, если нет данных в базе РСА либо указаны неправильные?
Содержание страницы
С 2013 года Союзом автостраховщиков РФ (РСА) введена в работу база данных, используемая при проверке коэффициента «бонус-малус» (КБМ). Указанный параметр в обязательном порядке должен использоваться страховыми компаниями при расчете тарифа по страхованию (ОСАГО).
Учитывая собственную страховую историю, водители могут рассчитывать на понижение тарифа за счет бонусов (5% за каждый год) за безаварийное вождение в предыдущий страхованию год. Если в ходе последних двух лет имело место ДТП по вине клиента, то размер тарифа увеличивается (малус).
В чем преимущества метода?
Для клиента выгода от единой базы данных состоит в том, что стоимость полиса должна ему объявляться сотрудником СК только после выполнения запроса в базу РСА и выявления права на получение скидки по стоимости. Ранее расчет часто производился по базовому тарифу без учета имеющегося бонуса.
Для страховой компании положительным моментом является возможность получения реальной картины по водительской истории клиента.
Почему нет сведений в базе?
Персональные данные в единой страховой базе могут отсутствовать по нескольким причинам:
- когда страховая компания по разным причинам не передала информацию об истории вождения клиента;
- когда переданы не правильные данные в РСА, а с ошибками, поэтому они не привязаны в базе к конкретному водителю;
- когда произошел технический сбой в работе программы и какие-то участки с данными оказались поврежденными;
- когда клиент произвел обмен водительского удостоверения, но информация в базе осталась привязанной к устаревшим данным;
- когда клиент только получил права и оформляет самый первый страховой договор.


Что делать при отсутствии информации в базе РСА?
Чтобы убедиться в том, что действительно нет данных в РСА о КБМ, следует направить письменный запрос в Союз автостраховщиков. Если не найдут подтверждения факты передачи сведений страховщиками за предыдущие периоды, водитель должен предпринять следующие действия:
- Подготовить старые страховые полисы ОСАГО. При их отсутствии обратиться в СК, где ранее оформлялись договора, и выяснить номера документов, период их действия и дату выдачи.
- По месту оформления предыдущего полиса получить справку для перехода в другую СК с указанием данных о страховом стаже клиента и страховых случаях (если таковые были).
- Полученную справку отнести в СК, где планируется оформление нового страхового соглашения.
Если договор уже оформлен, то на основании предоставленной справки стоимость полиса должна быть пересчитана, и возвращена часть оплаченной премии при наличии права на скидки (по КБМ).
Застраховать с ошибками: что показал новый сервис по проверке ОСАГО | Статьи
Автовладельцы могут получить штраф или вообще лишиться страховой выплаты, если при оформлении ОСАГО были указаны неверные данные. Так поступают недобросовестные посредники с целью оформить полис дешевле, а с автовладельца получить обычную сумму. Российский союз автостраховщиков (РСА) запустил сервис, с помощью которого автовладельцы самостоятельно могут проверить указанные в базе АИС ОСАГО сведения. Что делать, если в полисе обнаружились ошибки, разбирались «Известия».
Так поступают недобросовестные посредники с целью оформить полис дешевле, а с автовладельца получить обычную сумму. Российский союз автостраховщиков (РСА) запустил сервис, с помощью которого автовладельцы самостоятельно могут проверить указанные в базе АИС ОСАГО сведения. Что делать, если в полисе обнаружились ошибки, разбирались «Известия».
Пробить по базе
Раньше на сайте РСА можно было проверить, является ли полис действующим на момент ДТП. С помощью нового сервиса автовладелец сможет узнать, какие именно параметры были указаны при оформлении полиса — марка, модель и категория транспортного средства, мощность, узнать коэффициент бонус-малус, регион использования автомобиля, количество водителей, допущенных к управлению, и т.д. И, естественно, его цену.
В РСА сообщили «Известиям», что ограничились добавлением ключевых параметров, которые обычно искажаются недобросовестными посредниками и существенно влияют на цену полиса ОСАГО.
Что показала проверка
Кроме того, в сервисе указаны собственник и страхователь транспортного средства. И хотя все буквы, кроме первой, закрыты звездочками, имя, отчество и год рождения позволяют сопоставить указанных в остальных документах лиц. Это, как и срок действия страховки, важная информация, если ДТП уже произошло и у вас есть сомнения относительно другого участника аварии.
И хотя все буквы, кроме первой, закрыты звездочками, имя, отчество и год рождения позволяют сопоставить указанных в остальных документах лиц. Это, как и срок действия страховки, важная информация, если ДТП уже произошло и у вас есть сомнения относительно другого участника аварии.
Между тем проверка редакцией «Известий» девяти машин и одного мотоцикла оставила много вопросов. Например, корректный результат дает поиск по серии и номеру полиса, а также по VIN автомобиля. Если искать по госномеру, система в большинстве случаев ничего не находит либо отображает данные старого полиса и прежних владельцев машины.
Фото: ИЗВЕСТИЯ/Зураб Джавахадзе
Автоэксперт Игорь Моржаретто считает, что новый сервис еще будут дорабатывать, и положительно оценил его появление.
«Только когда покупаешь новый полис, выясняется, что у тебя странный какой-то КБМ. Начинаешь выяснять самостоятельно, а для этого нужен источник информации, нужна обратная связь, где я могу сказать: «Вы, ребята, неправы, у меня по-другому», — рассказал он.
Без номера и категории
Обычно госномер не попадает в базу, если автовладелец оформил ОСАГО до того, как поставил автомобиль на учет в ГИБДД. Однако у единственного проверенного мотоцикла не оказалось ни госномера, хотя транспортное средство было поставлено на учет, ни марки и модели, ни мощности. А в качестве категории было указано загадочное: «0 Прочее (категория «с»)». Даже в РСА не смогли объяснить этот термин. В Союзе пообещали дать ответ технического специалиста, но на момент сдачи материала комментарий не предоставили.
Фото: ИЗВЕСТИЯ/Дмитрий Коротаев
Отсутствие госномера автомобиля в базе теоретически грозит добросовестному автовладельцу штрафом, когда автоматическая проверка ОСАГО с помощью камер будет запущена. Проблемы могут возникнуть, подтвердили в РСА и попросили всех, получивших полис ОСАГО до регистрации ТС, сообщить в свою страховую компанию о присвоенном автомобилю госномере.
Внимание, работают мошенники
РСА и страховщики фиксирует большое количество попыток оформить полис ОСАГО с недостоверными сведениями.
«В данном случае стоит говорить о недобросовестных «посредниках», которые, используя незнание автовладельцев, оформляют полис ОСАГО онлайн и вводят недостоверные сведения, например цель использования, мощность и т.д., снижают стоимость полиса, а затем передают клиенту иной полис с иной стоимостью, разницу присваивая себе.
В практике «Согласия» есть такие прецеденты, подобные действия «посредников» носят мошеннический характер и наносят вред потребителю и репутации страховщика», — рассказала «Известиям» директор судебно-правового департамента страховой компании «Согласие» Анна Полина-Сташевская. И посоветовала оформлять полис е-ОСАГО, не требующий привлечения посредников.Президент РСА Игорь Юргенс отметил, что в настоящее время в системе АИС ОСАГО 2.0 работают фильтры, позволяющие отсеивать попытки оформить полис ОСАГО, указав при оформлении заведомо неверные данные.
Офис страховой компании
Фото: ТАСС/Сергей Николаев
«Однако никакие технические решения не могут на 100% защитить от мошенничества», — отметил он.
И действительно, в одном из проверенных «Известиями» полисов в графе «Цель использования» было указано «Учебная езда», хотя машина используется в личных целях. Почему посредник указал ее при оформлении полиса — загадка.
«Указание в графе «Цель использования» варианта «Учебная езда» в настоящее время не влияет на формирование страховой премии по ОСАГО, а также на получение страховой выплаты в случае страхового события. Однако стоит быть внимательным, возможны случаи, когда похожая ошибка может привести к регрессу. Например, если у автомобиля есть лицензия такси, но в страховом полисе указано, что транспортное средство используется для личных целей, в случае аварии страховая компания может выставить регресс лицу, причинившему вред», — рассказали в пресс-службе «Альфастрахования». Кроме того, если полис окажется оформленным на другую машину или другого страхователя, пострадавшему в ДТП вообще могут отказать в страховой выплате.
Ваш полис недействителен
Какой процент неверных сведений в полисе сделает его недействительным? Для договоров ОСАГО нет такого понятия — «процент неправильно указанных данных», уточнили в РСА.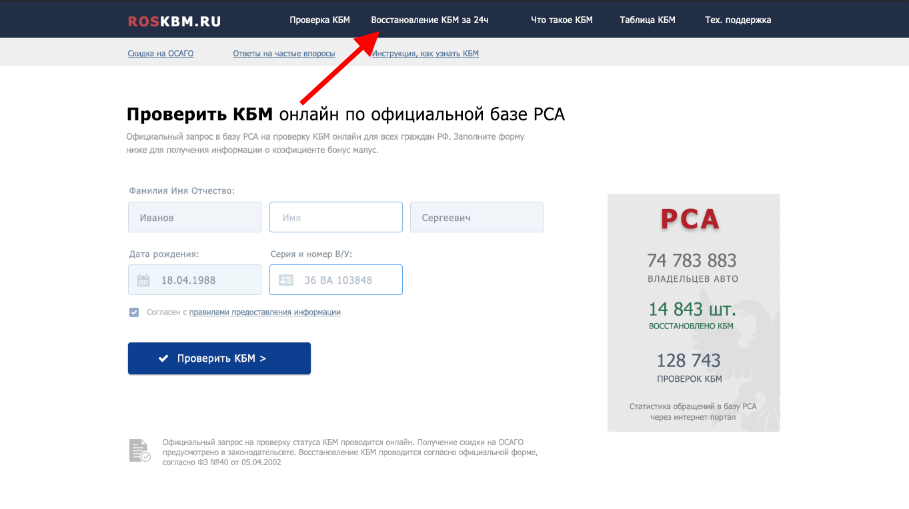 В Союзе добавили, что в каждом конкретном случае необходимо разбираться, была ли допущена опечатка или случайная ошибка либо данные были введены заведомо неверно.
В Союзе добавили, что в каждом конкретном случае необходимо разбираться, была ли допущена опечатка или случайная ошибка либо данные были введены заведомо неверно.
Федеральный закон об ОСАГО, Положение о правилах ОСАГО не содержат в себе указаний о проценте неправильных сведений, содержащихся в полисе ОСАГО, чтобы признать его недействительным, отметил ведущий юрист Европейской юридической службы Орест Мацала. По его словам, чтобы досрочно прекратить действие договора ОСАГО либо вовсе признать его недействительным, необходимо установить, что недостоверные сведения были представлены намеренно и это повлекло за собой необоснованное снижение стоимости ОСАГО.
Фото: ТАСС/Ведомости/Евгений Разумный
«Любые недостоверные сведения, которые непосредственно повлияли на размер страховой премии, позволяют страховщику досрочно прекратить договор страхования либо в дальнейшем предъявить регрессные требования в соответствии со ст. 14 закона об ОСАГО.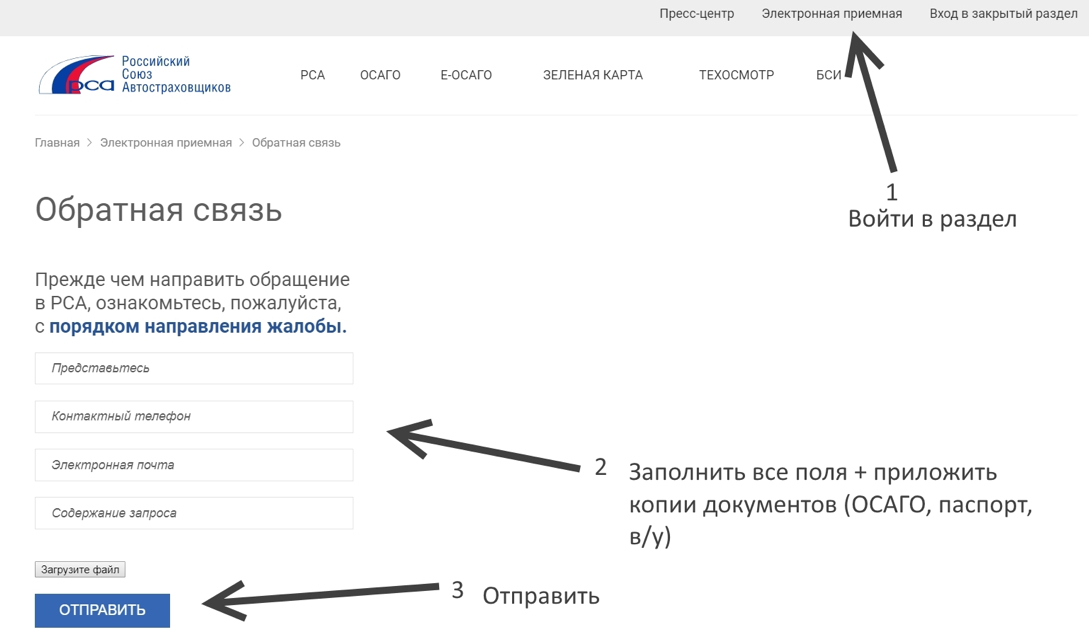
Пишите письма
Что делать, если при проверке полиса ОСАГО в базе обнаружились неверные сведения? Следует обратиться в страховую компанию и написать письменное заявление, чтобы изменения в договоре были сделаны. Если установлено, что имело место мошенничество, эксперты и страховщики рекомендуют обратиться и в правоохранительные органы.
Кроме того, у автовладельца есть шанс получить компенсацию через суд, считает Орест Мацала.
«Поскольку страхование ОСАГО — это услуга, при некачественно оказанной услуге, в том числе и при заключении договора, можно требовать компенсации всех убытков и возмещения морального вреда в соответствии со ст. 15 и 29 закона «О защите прав потребителей», — отметил ведущий юрист Европейской юридической службы.
15 и 29 закона «О защите прав потребителей», — отметил ведущий юрист Европейской юридической службы.
Не прошел проверку РСА. Что делать? » 711.ru
Зачем нужна проверка РСА
Проверка РСА в электронных полисах ОСАГО — обязательная процедура. Вы вводите информацию о своем автомобиле, себе (паспортные данные) и водителях, которые будут допущены к управлению. Страховая компания в зашифрованном виде отправляет эти сведения в базу данных РСА.
Проверка по базе РСА проходит в автоматическом режиме. Ее основная цель — проверить были ли у вас раньше полисы, какая по ним страховая история (количество аварий) и корректно рассчитать стоимость полиса.
Когда происходит проверка
Проверка по базе РСА запускается после того, как вы заполнили заявление на страхование для электронного полиса ОСАГО в личном кабинете на сайте страховой компании.
Без положительного прохождения проверки, вы не сможете перейти к оплате полиса.
Почему не проходит проверка РСА
Проверка не всегда проходит успешно. Нередко система страховщика не может выполнить ее.
Нередко система страховщика не может выполнить ее.
Причины непрохождения бывают разные. Технический сбой, отсутствие в базе информации по вам и вашей машине — самые распространенные из них.
Иногда встречается намеренная блокировка результатов проверки. Недобросовестные компании таким образом пытаются регулировать поток клиентов и отсеивать невыгодных — из “токсичных” регионов и с убытками по прошлым годам. Подобные действия запрещены и могут привести к болезненным санкциям для страховщиков со стороны РСА и ЦБ РФ.
Что делать, если не прошла проверка РСА
При оформлении электронного полиса ОСАГО на сайте страховой компании вам могут сообщить, что автоматическая проверка РСА не прошла.
Например, в Росгосстрахе это выглядит так:
Чтобы исправить ситуацию, вам предложат загрузить на сайт электронные копии следующих документов:
- паспорт страхователя — основная страница и страница с пропиской;
- паспорт транспортного средства — обе стороны;
- диагностическая карта;
- водительское удостоверение — обе стороны.

Безопасно ли это? Вполне. Доступ в личный кабинет для оформления Е-ОСАГО происходит по защищенному протоколу https (на всякий случай проверьте это в адресной строке браузера). Информация по документам попадет только в страховую компанию, которая не имеет права передавать ее третьим лицам.
Специалисты страховщика вручную проверят в базе данных РСА ваши данные по документам. И в течение 30 минут минут пришлют на электронную почту дальнейшие инструкции. От компании к компании время варьируется, но в среднем ждать дольше получаса не придется.
Результат ручной проверки в компании
Результатом ручной проверки документов сотрудниками страховой компании станет письмо.
К примеру, от Росгосстраха, приходит письмо следующего содержания.
В письме вам сообщат, что по документам у вас все в порядке, и вы всё правильно заполнили в заявлении на Е-ОСАГО.
Здесь же будет ссылка для входа в личный кабинет и продолжения оформления электронного полиса.
Для удобства клиентов, все данные, введенные в личном кабинете, сохраняются. Включая информацию по страхователю, автомобилю и водителям.
Останется только перейти в раздел оплаты и оплатить полис банковской картой.
Евгений Попков / 711.ru
Поделиться статьей:
Как восстановить КБМ в 2021 году? Как вернуть КБМ по ОСАГО после замены прав
Этапы восстановления КБМ
Первым этапом, чтобы восстановить КБМ, по базе РСА надо узнать самостоятельно свой коэффициент. Сервис бесплатный, в режиме онлайн на нём введите информацию о себе: ФИО, дату рождения и данные водительского удостоверения. После обработки выйдет информация обо всех изменениях показателя, по которым вы сможете отследить, где произошел сбой. Определив, в какой страховой компании ваш коэффициент завысили, вы сохраняете историю изменений вашего КБМ.
Далее отправляйте заявление в страховую компанию для проведения проверки и осуществления перерасчета на основании приложенных данных. При необходимости прикладывайте:
- справку из предыдущей страховой компании об отсутствии выплат по ущербу;
- документы, подтверждающие смену фамилии;
- копии старого и нового водительского удостоверения;
- предыдущий полис ОСАГО.
На рассмотрение заявления отводится 15 дней.
Как вернуть КБМ, если этот способ не сработал, или страховщик, который допустил оплошность, уже ликвидирован? Обращайтесь с жалобой в РСА и ЦБ. Заявления в данные инстанции можно также подавать в письменном или электронном виде, заполнив соответствующие формы на сайте. Список прилагаемых документов для подачи жалобы тот же, что и в предыдущем случае. При этом вам нужно указать страховую компанию, описать, с каким КБМ оформлялись полисы, и указать количество аварий в период страхования, а также приложить свое обращение в страховую компанию и ответ на него, если таковой последовал. Эта процедура занимает от до 60 дней.
При этом вам нужно указать страховую компанию, описать, с каким КБМ оформлялись полисы, и указать количество аварий в период страхования, а также приложить свое обращение в страховую компанию и ответ на него, если таковой последовал. Эта процедура занимает от до 60 дней.
После восстановления КБМ вы сможете пересчитать стоимость полиса и вернуть излишне оплаченные суммы, обратившись в страховую компанию.
Оформить полисКуда исчезает скидка на ОСАГО
Политика конфиденциальности
Введение
Мы стремимся уважать информацию личного характера, касающуюся посетителей нашего сайта. В настоящей Политике конфиденциальности разъясняются некоторые из мер, которые мы предпринимаем для защиты Вашей частной жизни.
Конфиденциальность информации личного характера
«Информация личного характера» обозначает любую информацию, которая может быть использована для идентификации личности, например, фамилия или адрес электронной почты.
Использование информации частного характера.
Информация личного характера, полученная через наш сайт, используется нами, среди прочего, для целей регистрирования пользователей, для поддержки работы и совершенствования нашего сайта, отслеживания политики и статистики пользования сайтом, а также в целях, разрешенных вами.
Раскрытие информации частного характера.
Мы нанимаем другие компании или связаны с компаниями, которые по нашему поручению предоставляют услуги, такие как обработка и доставка информации, размещение информации на данном сайте, доставка содержания и услуг, предоставляемых настоящим сайтом, выполнение статистического анализа. Чтобы эти компании могли предоставлять эти услуги, мы можем сообщать им информацию личного характера, однако им будет разрешено получать только ту информацию личного характера, которая необходима им для предоставления услуг. Они обязаны соблюдать конфиденциальность этой информации, и им запрещено использовать ее в иных целях.
Мы можем использовать или раскрывать Ваши личные данные и по иным причинам, в том числе, если мы считаем, что это необходимо в целях выполнения требований закона или решений суда, для защиты наших прав или собственности, защиты личной безопасности пользователей нашего сайта или представителей широкой общественности, в целях расследования или принятия мер в отношении незаконной или предполагаемой незаконной деятельности, в связи с корпоративными сделками, такими как разукрупнение, слияние, консолидация, продажа активов или в маловероятном случае банкротства, или в иных целях в соответствии с Вашим согласием.
Мы не будем продавать, предоставлять на правах аренды или лизинга наши списки пользователей с адресами электронной почты третьим сторонам.
Доступ к информации личного характера.
Если после предоставления информации на данный сайт, Вы решите, что Вы не хотите, чтобы Ваша Персональная информация использовалась в каких-либо целях, Вы можете исключить себя из списка ОНЭКСИМ, связавшись с нами по следующему адресу: info@ur29. ru
Наша практика в отношении информации неличного характера.
Мы можем собирать информацию неличного характера о Вашем посещении сайта, в том числе просматриваемые вами страницы, выбираемые вами ссылки, а также другие действия в связи с Вашим использованием нашего сайта. Кроме того, мы можем собирать определенную стандартную информацию, которую Ваш браузер направляет на любой посещаемый вами сайт, такую как Ваш IP-адрес, тип браузера и язык, время, проведенное на сайте, и адрес соответствующего веб-сайта.
Использование закладок (cookies).
Файл cookie — это небольшой текстовый файл, размещаемый на Вашем твердом диске нашим сервером. Cookies содержат информацию, которая позже может быть нами прочитана. Никакие данные, собранные нами таким путем, не могут быть использованы для идентификации посетителя сайта. Не могут cookies использоваться и для запуска программ или для заражения Вашего компьютера вирусами. Мы используем cookies в целях контроля использования нашего сайта, сбора информации неличного характера о наших пользователях, сохранения Ваших предпочтений и другой информации на Вашем компьютере с тем, чтобы сэкономить Ваше время за счет снятия необходимости многократно вводить одну и ту же информацию, а также в целях отображения Вашего персонализированного содержания в ходе Ваших последующих посещений нашего сайта. Эта информация также используется для статистических исследований, направленных на корректировку содержания в соответствии с предпочтениями пользователей.
Эта информация также используется для статистических исследований, направленных на корректировку содержания в соответствии с предпочтениями пользователей.
Агрегированная информация.
Мы можем объединять в неидентифицируемом формате предоставляемую вами личную информацию и личную информацию, предоставляемую другими пользователями, создавая таким образом агрегированные данные. Мы планируем анализировать данные агрегированного характера в основном в целях отслеживания групповых тенденций. Мы не увязываем агрегированные данные о пользователях с информацией личного характера, поэтому агрегированные данные не могут использоваться для установления связи с вами или Вашей идентификации. Вместо фактических имен в процессе создания агрегированных данных и анализа мы будем использовать имена пользователей. В статистических целях и в целях отслеживания групповых тенденций анонимные агрегированные данные могут предоставляться другим компаниям, с которыми мы взаимодействуем.
Изменения, вносимые в настоящее Заявление о конфиденциальности.
Мы сохраняем за собой право время от времени вносить изменения или дополнения в настоящую Политику конфиденциальности — частично или полностью. Мы призываем Вас периодически перечитывать нашу Политику конфиденциальности с тем, чтобы быть информированными относительно того, как мы защищаем Вашу личную информацию. С последним вариантом Политики конфиденциальности можно ознакомиться путем нажатия на гипертекстовую ссылку «Политика конфиденциальности», находящуюся в нижней части домашней страницы данного сайта. Во многих случаях, при внесении изменений в Политику конфиденциальности, мы также изменяем и дату, проставленную в начале текста Политики конфиденциальности, однако других уведомлений об изменениях мы можем вам не направлять. Однако, если речь идет о существенных изменениях, мы уведомим Вас, либо разместив предварительное заметное объявление о таких изменениях, либо непосредственно направив вам уведомление по электронной почте. Продолжение использования вами данного сайта и выход на него означает Ваше согласие с такими изменениями.
Продолжение использования вами данного сайта и выход на него означает Ваше согласие с такими изменениями.
Связь с нами.
Если у Вас возникли какие-либо вопросы или предложения по поводу нашего положения о конфиденциальности, пожалуйста, свяжитесь с нами по следующему адресу: [email protected]
Как проверить подлинность страхового полиса ОСАГО?
Содержание статьи:
Страховой рынок всегда привлекал мошенников. Чтобы не стать их жертвой, автовладельцам не следует терять бдительность
и обязательно проверять подлинность страхового полиса. В случае с полисом обязательного страхования гражданской
ответственности владельцев транспортных средств (ОСАГО), сделать это можно с помощью единой автоматизированной
информационной системы Российского союза автостраховщиков (РСА), в которой фиксируются все договоры «автогражданки».
Именно участившиеся случаи подделки бланков ОСАГО, использование мошенниками утраченных полисов, а также страховок уже
не существующих компаний, у которых была отозвана лицензия, привели к тому, что РСА разработал федеральную систему для
проверки их подлинности.
ОСАГО
Покупая полис ОСАГО, обратите внимание на размер бланка (он больше формата А4 примерно на 1 см), на наличие водяных знаков защиты с логотипом РСА. Кроме того, на бланке должны быть разноцветные ворсинки, а по левому краю проходить металлическая полоска. Номер оригинального полиса содержит 3 буквы (серия договора) и 10 цифр (номер бланка строгой отчетности – БСО). При этом, все цифры на бланке – выпуклые. Для бумажных полисов ОСАГО сейчас действует серия РРР/ННН.
Очень важно, чтобы сумма страховой премии в договоре совпадала с суммой денег, которую вы платите за полис. Конечно, при оплате вам обязаны выдать квитанцию.
Фальшивые бланки
Поддельные полисы ОСАГО злоумышленники изготавливают специально или воруют у страховой компании, но такие случаи очень редки. Крупные страховые компании серьезно следят за сохранностью ОСАГО, бумажная версия которых является бланками строгой отчетности (БСО).
Также поддельными являются бланки, которые принадлежат страховой компании с отозванной лицензией на ведение страховой
деятельности.
Проверка на подлинность. База РСА
База РСА бесплатная и доступна абсолютно всем автовладельцем на официальном сайте организации — https://autoins.ru/. Проверить подлинность ОСАГО просто: перейдите в одноименную вкладку, выбрав после этого опцию «Проверка полиса». Вам не потребуются ни авторизация, ни регистрация, только сведения из документа, который есть у вас на руках или в электронном виде. Система обрабатывает данные и выдает результат мгновенно.
Мобильное приложение «Помощник ОСАГО»
В прошлом году в нескольких пилотных регионах заработало мобильное приложение «Помощник ОСАГО». В ноябре 2020 года мобильное приложение доступно для автовладельцев со всех уголков России. Один из создателей «Помощника ОСАГО» — РСА, поэтому проверить полис ОСАГО на подлинность в приложении так же просто, как и на официальном сайте организации. Скачать приложение можно в AppStore и Google Play.
Гос. номер, VIN код, номер кузова и шасси автомобиля
Проверить полис ОСАГО на подлинность с помощью VIN-номера, государственного регистрационного знака, номера кузова и
шасси автомобиля важно для тех, кто хочет купить машину. Такой способ проверки подлинности полиса наиболее полный, вы
получите информацию – действителен ли полис ОСАГО, кто вписан в него (если тип страховки ограничен).
Такой способ проверки подлинности полиса наиболее полный, вы
получите информацию – действителен ли полис ОСАГО, кто вписан в него (если тип страховки ограничен).
https://autoins.ru/ -> ОСАГО -> Проверка полиса ОСАГО -> Реквизиты транспортного средства.
Результаты запроса в базу РСА
Сведения, полученные в базе РСА, гарантированно достоверные. Все дело в том, что в единую систему вносить данные могут только страховые компании. Особенно важно обращаться к проверенным страховщиком, давно работающим на страховом рынке и зарекомендовавшим себя.
Если вы столкнулись с мошенниками, то при проверке полиса, вы увидите сообщения – «Утратил силу» или «Утерян». Такие статусы свидетельствуют о том, что договор недействителен.
В отношении подлинных полисов «автогражданки» система выдает статусы – «Находится у страховщика» (если вы купили
полис, но менеджер компании пока не успел внести данные в базу РСА) или «Находится у страхователя».
Статус «Находится у страхователя» – самый правильный. Обратите внимание, что срок страхования и название страховой компании должны совпадать с данными, которые содержаться в договоре. К сожалению, если мошенники продали вам дубликат страхового полиса, то вы тоже увидите статус «Находится у страхователя». Проверьте на сайте РСА, какая машина застрахована по полису и имейте ввиду, что полис – дубликат от мошенников, если сведения не совпали.
Если ваш полис «Находится у страховщика» и уже довольно давно, стоит связаться с компанией с просьбой прояснить ситуацию.
Проверка не дала результатов. Что делать?
Скорее всего, вы столкнулись со злоумышленниками. Для начала свяжитесь со страховой компанией, указанной в полисе.
Электронный полис ОСАГО
Е-ОСАГО – выбор многих современных людей. Полис электронный, но защита по нему реальная, полис равноценен бумажной
версии. Однако электронный полис не убережет от мошенников, которые подделывают даже сайты, предлагая водителям
приобрести ОСАГО.
Покупайте полисы на официальных сайтах страховых компаний. Обратите внимание, что серия полисов е-ОСАГО начинается с XXX.
Заключение
Если вы столкнулись с мошенниками, обратитесь в полицию. Пишите заявление и требуйте завести уголовное дело, приложив доказательства того, что ваш полис ОСАГО – поддельный.
Надежные страховые компании дорожат своей репутацией. Как правило, вопросы с поддельными бланками ОСАГО решаются на уровне службы безопасности страховой компании. Обращайтесь к проверенным страховщикам, оформляйте договор в официальных офисах продаж страховых компаний, онлайн на сайтах страховщиков, обращайте внимание на наличие агентского договора у страхового представителя и проверяйте его подлинность, позвонив в компанию. Будьте спокойны за то, что ваш полис ОСАГО – действительный.
Как восстановить КБМ в РСА
Нередки ситуации допущения ошибок в расчетах стоимости полиса ОСАГО, когда страховщик забывает или неверно определяет коэффициент водителя за безаварийную езду. Чтобы избежать завышенной оплаты, вы можете сами контролировать показатель скидки, периодически отправляя заявку на проверку КБМ по инструкции на сайте: https://roskbm.ru/kak-uznat-kbm.
Чтобы избежать завышенной оплаты, вы можете сами контролировать показатель скидки, периодически отправляя заявку на проверку КБМ по инструкции на сайте: https://roskbm.ru/kak-uznat-kbm.
Почему скидка на ОСАГО пропала
Нередки случаи, когда при проверке КБМ обнаруживается пропажа или значительное уменьшение скидки на страховой полис. Если вам вернули стандартный класс и КБМ=1, нужно разобраться в причинах и исправить ситуацию.
Как накопить КБМ на скидку
- Год безаварийной езды дает скидку 5% и повышает класс на один.
Если с момента последнего страхования автомобиля прошло менее 12 месяцев, скидка не положена. Аналогично происходит и в случаях вписывания третьих лиц (жены, друга) в страховку в середине срока действия полиса.
-
Скидка на полис действует при непрерывном страховании автогражданской ответственности.

После прекращения действия страхового договора скидка остается только на год. Если перерыв в страховании дольше 12 месяцев, дисконт сгорает, нужно начинать копить КБМ с начала.
- Максимальный размер скидки 50 % достигается спустя 10 лет непрерывного вождения без аварий по вине водителя – это самый последний, 13 класс.
После достижения последнего класса последующие классы будут тоже под значением 13, пока вы не попадаете в аварию, и класс не снизится.
Ошибки в запросе на проверку КБМ
Часто ошибочный ответ на запрос выпадает при введении ошибочных данных владельца автомобиля. Если вы поменяли фамилию, в базе содержатся старые данные: обратите внимание на поле «Старая фамилия, если меняли» на странице заполнения формы для восстановления КБМ. Попробуйте ввести старые данные, и тогда увидите действующий КБМ и размер скидки на ОСАГО.
Аналогичная ситуация в случае с заменой водительских прав: введите номер прежнего водительского удостоверения (его можно узнать в разделе «Особые отметки» нового документа) и отправьте запрос.
Ошибка в КБМ по другим полисам
Иногда друзья и родственники вписывают друг друга в страховку на автомобиль, и если это ваш случай, стоит проверить значения КБМ в каждом из полисов, где значится ваша фамилия.
Ошибка могла произойти на стадии расчетов полиса другого человека, когда страховой агент случайно обнуляет скидки по всем полисам с одной фамилией, а владельцы машин не обращают внимания на ее отсутствие. В итоге вы попадаете в базу РСА с обнуленной скидкой, которую придется восстановить. При заполнении формы на проверку КБМ можно проверить, какой страховой полис утратил скидку.
Ошибки в КБМ в базе РСА онлайн
При возникновении проблем с расчетом скидки на ОСАГО страховщики любят ссылаться на ошибки в официальной базе РСА. Но часто это происходит именно по вине страхового агента, который вносит ваши данные в базу с ошибкой.
Дата рождения, фамилия, номер и серия водительского удостоверения – малейшая опечатка в этих сведениях приводит к нулевой скидке и начальному КБМ. Иногда в действиях страховщиков имеется прямой умысел: занесение данных с незаметной опечаткой – буква О вместо цифры 0 в дате рождения – не отображается в полисе ОСАГО и не может быть проверено вами на месте. Обнаружить ошибку можно при запросе справки о безубыточности, где указаны все данные из базы РСА.
Иногда в действиях страховщиков имеется прямой умысел: занесение данных с незаметной опечаткой – буква О вместо цифры 0 в дате рождения – не отображается в полисе ОСАГО и не может быть проверено вами на месте. Обнаружить ошибку можно при запросе справки о безубыточности, где указаны все данные из базы РСА.
Поддельный полис ОСАГО
Если вы страховали автомобиль на сайте непроверенного страховщика, есть риск приобрести липовую страховку. В таком случае естественно, что данные страхового полиса не отображаются в базе РСА – потому что их нет. Также сведения о страховании могут отсутствовать, если страховщик не передал их в базу. Сегодня случаи утраты договора практически исключены, потому что заключение оформляется на компьютере, а не вручную. Но если агент выписал бумажный вариант полиса и случайно утратил его по дороге в страховую, в базу РСА вы вряд ли попадете.
Намеренное сокрытие скидки ОСАГО
Страхование – доходный бизнес, и потому понятно желание страхового агента продать полис подороже. Нередки ситуации намеренного скрывания скидки от страхователя с целью получения крупной комиссии. Финансовая безграмотность клиентов страховой компании играет на руку нечистоплотным страховщикам. Вас могут обмануть сообщением об отсутствии связи с базой РСА или зависании компьютера. Поэтому следует заранее выяснить свой КБМ и положенную скидку, чтобы с этими сведениями идти страховать личный автомобиль.
Нередки ситуации намеренного скрывания скидки от страхователя с целью получения крупной комиссии. Финансовая безграмотность клиентов страховой компании играет на руку нечистоплотным страховщикам. Вас могут обмануть сообщением об отсутствии связи с базой РСА или зависании компьютера. Поэтому следует заранее выяснить свой КБМ и положенную скидку, чтобы с этими сведениями идти страховать личный автомобиль.
Как вернуть скидку на ОСАГО
Коэффициент бонус-малус влияет на конечную сумму по оплате страхового полиса. Размер КБМ зависит от количества лет, в течение которых у водителя отсутствовали ДТП по его вине. Чем идеальнее водительская история, тем выше скидка на ОСАГО, которая может достигать 50% в зависимости от тарифа КБМ. Вы можете ознакомиться с таблицей КБМ 2020 года и узнать свой тариф по ссылке: https://roskbm.ru/kbm-tablica.
Введение коэффициента для расчета стоимости полиса стимулирует водителя на аккуратную, безаварийную езду. Если за 10 лет стажа вы не попали ни в одну аварию, полис ОСАГО будет стоить в два раза меньше обычной цены.
Если за 10 лет стажа вы не попали ни в одну аварию, полис ОСАГО будет стоить в два раза меньше обычной цены.
Но не всегда сведения о скидке содержатся в базе РСА, нередки случаи ошибок и упущений, из-за которых водитель лишается бонусов при заключении страхового договора. Это может случиться после замены водительского удостоверения, изменения фамилии, в случае перерыва в страховании больше года, но чаще всего – если страховщик просто не передал ваши данные в базу РСА онлайн.
КБМ после замены ВУ
Нередко после замены водительских прав КБМ возвращается к начальному 3 классу и значению 1, а скидка на ОСАГО обнуляется. Чтобы избежать проблем с получением скидки при продлении страхового полиса, необходимо наличие обновленных данных в базе РСА.
Обновление данных водительского удостоверения требует обращения в страховую компанию и внесения изменений в полис ОСАГО.
Страхователь обязан незамедлительно сообщить в письменной форме страховщику об изменении сведений, указанных в договоре страхования, произошедших в период действия полиса.
Если вы поменяли права или сменили фамилию, необходимо сразу сообщить об этом своему страховому агенту, чтобы он внес изменения в страховой договор и базу РСА. Это касается и случаев изменения личных данных других водителей, вписанных в вашу страховку и допущенных к управлению автомобилем. В случае несвоевременного внесения данных ваша скидка может обнулиться, и для продления полиса придется заново восстанавливать КБМ.
Честный и опытный страховой агент легко решит проблему, если обратит внимание на графу «Особые отметки» и предложит ввести номер предыдущего водительского удостоверения или старую фамилию. Он найдет скидку, сделает новый расчет КБМ и продаст полис ОСАГО по заниженной цене.
Как восстановить КБМ
Если скидка на полис ОСАГО была утрачена, необходимо восстановить КБМ. Первый и самый простой способ восстановить коэффициент бонус-малус: отправить запрос в онлайн базу РСА через специальные сервисы, например, на сайте https://roskbm. ru/. Чтобы восстановить КБМ, зайдите на сайт и следуйте инструкции, по выполнению которой вы сможете вернуть коэффициент к исходному значению.
ru/. Чтобы восстановить КБМ, зайдите на сайт и следуйте инструкции, по выполнению которой вы сможете вернуть коэффициент к исходному значению.
1. В горизонтальном меню главной страницы сайта выберите раздел «Восстановление КБМ за 24 часа» или перейдите по ссылке: https://roskbm.ru/vosstanovit-kbm.
2. Заполните поля заявки: введите ФИО, дату рождения, сведения из старого и текущего водительских удостоверений, в случае смены фамилии не забудьте указать старую фамилию в отдельной графе.
3. После заполнения данных нажмите кнопку «Далее»: через 30 секунд на экране отобразится ваш КБМ и сумма скидки, которую вы должны получить при оплате полиса ОСАГО. В случае загруженности базы РСА, заполните поле с адресом электронной почты – мы направим ответ на запрос туда.
4. Чтобы восстановить КБМ, введите электронную почту и оплатите услугу, после зачисления оплаты запрос на восстановление будет направлен в онлайн базу РСА.
Чтобы восстановить КБМ, введите электронную почту и оплатите услугу, после зачисления оплаты запрос на восстановление будет направлен в онлайн базу РСА.
В письме будет указан номер заявки, по всем вопросам оформления и восстановления КБМ можно обратиться в техподдержку по адресу: [email protected]. После успешной обработки запроса вы получите письмо с результатом восстановления коэффициента, который можно проверить в официальной базе РСА. Мы гарантируем восстановление КБМ, в противном случае вернем деньги за оплату услуги.
Как восстановить КБМ бесплатно
Кроме онлайн обращения в базу РСА, вы можете лично подать заявление на восстановление коэффициента в свою страховую компанию, либо своевременно сообщить об изменении данных водительского удостоверения или гражданского паспорта.
Нередки случаи внесения завышенной оплаты по полису ОСАГО, на которые водитель не обращает внимания. Неправильные расчеты страхового агента, ошибка в базе, спешка или халатное отношение к процедуре переоформления договора страхования становятся причинами неверного применения коэффициента бонус-малус и утраты скидки.
Неправильные расчеты страхового агента, ошибка в базе, спешка или халатное отношение к процедуре переоформления договора страхования становятся причинами неверного применения коэффициента бонус-малус и утраты скидки.
Вы должны выяснить, на каком этапе и когда были внесены ошибочные сведения, для этого достаточно заполнить данные в полях заявки на проверку КБМ и выбрать услугу «История изменения КБМ с 2013 года». Полученные сведения приложите к заявлению и направьте в страховую компанию с требованием произвести перерасчет КБМ и положенной скидки на основании обновленной информации. Не забудьте при наличии приложить дополнительные документы:
- предыдущий полис ОСАГО,
- копии старых и новых водительских прав,
- копию документов, подтверждающих изменение фамилии,
- справку из предыдущей страховой компании об отсутствии выплат по ущербу в ДТП.
Если спустя 10 дней страховщик не рассмотрел заявление, подавайте жалобу в РСА или ЦБ. Жалобу можно подать в простой письменной форме или в электронном виде через заполнение заявки на сайте. Не забудьте:
Жалобу можно подать в простой письменной форме или в электронном виде через заполнение заявки на сайте. Не забудьте:
- Приложить выше названные документы, копию обращения в страховую и ответ на него (при наличии).
- Указать страховую компанию.
- Описать, с каким КБМ ранее оформлялись полисы ОСАГО.
- Обозначить число аварий в период страхования.
Жалоба в РСА или ЦБ рассматривается в течение 60 суток. После восстановления КБМ страховая компания пересчитает стоимость полиса и вернет излишне уплаченные суммы.
Анализ основных компонентов неполных данных — простое решение старой проблемы
Основные моменты
- •
Стандартный алгоритм PCA изменен для учета неполных данных.
- •
Метод позволяет получать оценки ординации для переменных и наблюдений одновременно.
- •
Информация максимально исчерпана, вменение данных не требуется.
- •
Разрешены переменные, которые логически невозможны для определенных наблюдений.
- •
Имеет значение количество переменных, а не процент неизвестных оценок.

Реферат
Давняя проблема анализа биологических данных — непреднамеренное отсутствие значений для некоторых наблюдений или переменных, что препятствует использованию стандартных многомерных исследовательских методов, таких как анализ главных компонент (PCA). Решения включают удаление частей данных, из-за которых информация теряется, вменение данных, которое всегда является произвольным, и ограничение анализа либо переменными, либо наблюдениями, что приводит к потере преимуществ двумерных диаграмм.Мы описываем небольшую модификацию PCA на основе собственного анализа, в которой корреляции или ковариации вычисляются с использованием разного количества наблюдений для каждой пары переменных, а полученные собственные значения и собственные векторы используются для вычисления оценок компонентов, так что пропущенные значения пропускаются. Эта процедура позволяет избежать искусственного вменения данных, исчерпывает всю информацию из данных и позволяет подготовить биплоты для одновременного отображения ординации переменных и наблюдений.Использование модифицированного PCA, называемого InDaPCA (PCA неполных данных), продемонстрировано на реальных биологических примерах: функциональные признаки листьев растений, функциональные признаки беспозвоночных, морфометрия черепа крокодилов и данные гибридизации рыб — с биологически значимыми результатами. Наше исследование показывает, что значение имеет не процент пропущенных записей в матрице данных; На успех InDaPCA в основном влияет минимальное количество наблюдений, доступных для сравнения данной пары переменных.Однако в настоящем исследовании не было препятствий для интерпретации результатов в пространстве первых двух компонентов.
Эта процедура позволяет избежать искусственного вменения данных, исчерпывает всю информацию из данных и позволяет подготовить биплоты для одновременного отображения ординации переменных и наблюдений.Использование модифицированного PCA, называемого InDaPCA (PCA неполных данных), продемонстрировано на реальных биологических примерах: функциональные признаки листьев растений, функциональные признаки беспозвоночных, морфометрия черепа крокодилов и данные гибридизации рыб — с биологически значимыми результатами. Наше исследование показывает, что значение имеет не процент пропущенных записей в матрице данных; На успех InDaPCA в основном влияет минимальное количество наблюдений, доступных для сравнения данной пары переменных.Однако в настоящем исследовании не было препятствий для интерпретации результатов в пространстве первых двух компонентов.
Ключевые слова
Биплот
Корреляция
Функциональный признак
Отсутствующие данные
Морфометрия
Порядок
Аббревиатуры
InDaPCAРекомендуемые статьи
Корреляция
Основные компоненты
Анализ парных данных
© 2021 Автор (ы). Опубликовано Elsevier B.V.
Опубликовано Elsevier B.V.Рекомендуемые статьи
Цитирование статей
Приведение в порядок с помощью PCA: Введение в анализ основных компонентов | Сидней Фирмин
Анализ главных компонентов (PCA) — это метод уменьшения размерности, который представляет собой процесс уменьшения количества переменных-предикторов в наборе данных.
Более конкретно, PCA — это неконтролируемый тип извлечения признаков, при котором исходные переменные объединяются и сокращаются до их наиболее важных и описательных компонентов.
Цель PCA — выявить закономерности в наборе данных, а затем выделить переменные до их наиболее важных характеристик, чтобы упростить данные без потери важных характеристик. PCA спрашивает, вызывают ли радость все измерения набора данных, а затем дает пользователю возможность исключить те, которые этого не делают.
PCA — очень популярный метод, но его часто не понимают люди, применяющие его. Моя цель в этом сообщении в блоге — дать общий обзор того, зачем использовать PCA, а также как это работает.
Проклятие размерности (или зачем беспокоиться об уменьшении размерности?)
Проклятие размерности — это совокупность явлений, которые утверждают, что по мере увеличения размерности, управляемость и эффективность данных имеют тенденцию к снижению . На высоком уровне проклятие размерности связано с тем фактом, что по мере добавления размеров (переменных / характеристик) к набору данных среднее и минимальное расстояние между точками (записями / наблюдениями) увеличивается.
Я считаю, что визуализация переменных в виде измерений и наблюдений в виде записей / точек помогает, когда я начинаю думать о таких темах, как кластеризация или PCA. Каждая переменная в наборе данных представляет собой набор координат для построения наблюдения в проблемном пространстве.
Создание хороших прогнозов становится более трудным, поскольку расстояние между известными точками и неизвестными точками увеличивается. Кроме того, функции в вашем наборе данных могут не добавить большой ценности или предсказательной силы в контексте целевой (независимой) переменной. Эти функции не улучшают модель, скорее они увеличивают шум в наборе данных, а также общую вычислительную нагрузку модели.
Эти функции не улучшают модель, скорее они увеличивают шум в наборе данных, а также общую вычислительную нагрузку модели.
Из-за проклятия размерности уменьшение размерности часто является критическим компонентом аналитических процессов. Особенно в приложениях, где данные имеют высокую размерность, например компьютерное зрение или обработка сигналов.
При сборе данных или применении набора данных не всегда очевидно или легко узнать, какие переменные важны.Нет даже гарантии, что переменные, которые вы выбрали или были предоставлены, являются переменными правильными . Кроме того, в эпоху больших данных огромное количество переменных в наборе данных может выйти из-под контроля и даже сбить с толку и ввести в заблуждение. Это может затруднить (или сделать невозможным) выбор значимых переменных вручную.
Не бойтесь, PCA смотрит на общую структуру непрерывных переменных в наборе данных, чтобы извлечь значимые сигналы из шума в наборе данных.Он направлен на устранение избыточности в переменных при сохранении важной информации.
PCA тоже любит беспорядок.
Как работает PCA
PCA родом из области линейной алгебры. Это метод преобразования, который создает (взвешенные линейные) комбинации исходных переменных в наборе данных с намерением, чтобы новые комбинации улавливали как можно большую дисперсию (т. Е. Разделение между точками) в наборе данных, устраняя при этом корреляции ( я.е., избыточность).
PCA создает новые переменные путем преобразования исходных (центрированных по среднему) наблюдений (записей) в наборе данных в новый набор переменных (измерений) с использованием собственных векторов и собственных значений, вычисленных из ковариационной матрицы исходных переменных.
Это полный рот. Давайте разберемся с этим, начав со среднего значения исходных переменных.
Первым шагом PCA является центрирование значений всех входных переменных (например, вычитание среднего значения каждой переменной из значений), при котором среднее значение каждой переменной становится равным нулю. Центрирование является важным этапом предварительной обработки, поскольку оно гарантирует, что результирующие компоненты смотрят только на дисперсию в наборе данных, а не фиксируют общее среднее значение набора данных в качестве важной переменной (измерения). Без центрирования среднего первый главный компонент, найденный PCA, мог бы соответствовать среднему значению данных, а не направлению максимальной дисперсии.
Центрирование является важным этапом предварительной обработки, поскольку оно гарантирует, что результирующие компоненты смотрят только на дисперсию в наборе данных, а не фиксируют общее среднее значение набора данных в качестве важной переменной (измерения). Без центрирования среднего первый главный компонент, найденный PCA, мог бы соответствовать среднему значению данных, а не направлению максимальной дисперсии.
После того, как данные центрированы (и, возможно, масштабированы, в зависимости от единиц переменных), необходимо вычислить ковариационную матрицу данных.
Ковариация измеряется между двумя переменными (измерениями) одновременно и описывает, как значения переменных связаны друг с другом: например, поскольку наблюдаемые значения увеличения переменной x одинаковы для переменной y? Большое значение ковариации (положительное или отрицательное) указывает на то, что переменные имеют сильную линейную связь друг с другом. Значения ковариации, близкие к 0, указывают на слабую или несуществующую линейную связь.
Эта визуализация из https: // stats.stackexchange.com/questions/18058/how-would-you-explain-covariance-to-someone-who-understands-only-the-mean очень полезен для понимания ковариации.
Ковариация всегда измеряется в двух измерениях. Если вы имеете дело с более чем двумя переменными, наиболее эффективный способ убедиться, что вы получили все возможные значения ковариации, — это поместить их в матрицу (следовательно, матрицу ковариации). В ковариационной матрице диагональ — это дисперсия для каждой переменной, а значения по диагонали являются зеркалом друг для друга, потому что каждая комбинация переменных включается в матрицу дважды.Это квадратная симметричная матрица.
В этом примере дисперсия переменной A составляет 0,67, а дисперсия второй переменной — 0,25. Ковариация между двумя переменными составляет 0,55, что отражается на главной диагонали матрицы.
Поскольку ковариационные матрицы квадратные и симметричные, их можно диагонализовать, что означает, что для матрицы можно вычислить собственное разложение. Здесь PCA находит собственные векторы и собственные значения для набора данных.
Здесь PCA находит собственные векторы и собственные значения для набора данных.
Собственный вектор линейного преобразования — это (ненулевой) вектор, который изменяется на скалярное кратное самому себе, когда к нему применяется соответствующее линейное преобразование.Собственное значение — это скаляр, связанный с собственным вектором. Самая полезная вещь, которую я нашел для понимания собственных векторов и значений, — это увидеть пример (если это не имеет смысла, попробуйте посмотреть этот урок умножения матриц от Khan Acadamy).
Мне сказали, что использование * для умножения матриц — это необычное явление, но я оставил его для ясности. Приношу свои извинения любому оскорбленному математику, читающему это.
В этом примере
— это собственный вектор, а 5 — собственное значение.
В контексте понимания PCA на высоком уровне все, что вам на самом деле нужно знать о собственных векторах и собственных значениях, — это то, что собственные векторы ковариационной матрицы являются осями основных компонентов в наборе данных. Собственные векторы определяют направления главных компонентов, вычисляемых с помощью PCA. Собственные значения, связанные с собственными векторами, описывают величину собственного вектора или насколько далеко разнесены наблюдения (точки) вдоль новой оси.
Собственные векторы определяют направления главных компонентов, вычисляемых с помощью PCA. Собственные значения, связанные с собственными векторами, описывают величину собственного вектора или насколько далеко разнесены наблюдения (точки) вдоль новой оси.
Первый собственный вектор будет охватывать наибольшую дисперсию (разделение между точками), обнаруженную в наборе данных, а все последующие собственные векторы будут перпендикулярны (или, говоря математическим языком, ортогональны) к вычисленному перед ним.Вот как мы можем узнать, что каждый из основных компонентов не будет коррелирован друг с другом.
Если вы хотите узнать больше о собственных векторах и собственных значениях, в Интернете есть множество ресурсов, разбросанных именно с этой целью. Для краткости я не буду пытаться преподавать линейную алгебру (плохо) в сообщениях в блоге.
Каждый собственный вектор, найденный PCA, выбирает комбинацию отклонений от исходных переменных в наборе данных.
На этом рисунке Главный компонент 1 учитывает отклонения от обеих переменных A и B.
Собственные значения важны, потому что они обеспечивают критерий ранжирования для вновь полученных переменных (осей). Основные компоненты (собственные векторы) сортируются по убыванию собственного значения. Главные компоненты с наивысшими собственными значениями «выбираются первыми» как главные компоненты, поскольку они составляют наибольшую дисперсию данных.
Вы можете указать, что возвращает почти столько основных компонентов, сколько переменных в исходном наборе данных (обычно до n-1, где n — количество исходных входных переменных), но большая часть дисперсии будет учтена в главные основные компоненты.Чтобы узнать, сколько основных компонентов выбрать, ознакомьтесь с этим обсуждением переполнения стека. Или вы всегда можете просто спросить себя: «Я, сколько измерений вызовет радость?» (Это была шутка, вам, вероятно, следует просто использовать график осыпи.)
График осыпи показывает дисперсию, зафиксированную каждым главным компонентом. Этот график Scree был создан для вывода отчета инструмента «Основные компоненты» в Alteryx Designer.
После определения основных компонентов набора данных наблюдения исходного набора данных необходимо преобразовать в выбранные основные компоненты.
Чтобы преобразовать наши исходные точки, мы создаем матрицу проекции. Эта матрица проекции — это просто выбранные собственные векторы, объединенные в матрицу. Затем мы можем умножить матрицу наших исходных наблюдений и переменных на нашу матрицу проекции. Результатом этого процесса является преобразованный набор данных, проецируемый в наше новое пространство данных, состоящий из наших основных компонентов!
Вот и все! Мы завершили СПС.
Допущения и ограничения
Перед применением PCA необходимо учесть несколько моментов.
Нормализация данных перед выполнением PCA может быть важной, особенно когда переменные имеют разные единицы или масштабы. Вы можете сделать это в инструменте «Дизайнер», выбрав опцию Масштабировать каждое поле, чтобы иметь отклонение единиц измерения.
PCA предполагает, что данные могут быть аппроксимированы линейной структурой и что данные могут быть описаны с меньшим количеством функций. Он предполагает, что линейное преобразование может и будет захватывать наиболее важные аспекты данных. Также предполагается, что высокая дисперсия данных означает высокое отношение сигнал / шум.
Уменьшение размерности действительно приводит к потере некоторой информации. Из-за того, что не сохраняются все собственные векторы, некоторая информация теряется. Однако, если собственные значения собственных векторов, которые не включены, малы, вы не теряете слишком много информации.
Еще одно соображение, которое следует учитывать при использовании PCA, заключается в том, что переменные становятся менее интерпретируемыми после преобразования. Входная переменная может означать что-то конкретное, например, «воздействие УФ-излучения», но переменные, созданные PCA, представляют собой беспорядочную смесь исходных данных и не могут быть интерпретированы однозначно, например, «увеличение воздействия УФ-излучения коррелирует с увеличением наличие рака кожи.«Менее интерпретируемый также означает менее объяснимый, когда вы предлагаете свои модели другим.
Сильные стороны
PCA популярен, потому что он может эффективно находить оптимальное представление набора данных с меньшим количеством измерений. Он эффективен при фильтрации шума и уменьшении избыточности. Если у вас есть набор данных с множеством непрерывных переменных, и вы не знаете, как выбрать важные функции для целевой переменной, PCA может идеально подойти для вашего приложения.Аналогичным образом, PCA также популярен для визуализации наборов данных с высокой размерностью (потому что нам, скудным людям, трудно мыслить более чем в трех измерениях).
Дополнительные ресурсы
Мой любимый учебник (который включает в себя обзор лежащих в основе математики) принадлежит Линдси И. Смит из Университета Отаго. Учебник по анализу основных компонентов.
Вот еще один отличный учебник по анализу основных компонентов от Джона Шленса из UCSD
Все, что вы знали и не знали о PCA, из блога Its Neuronal посвящено математике и вычислениям в нейробиологии.
«Анализ главных компонентов за 3 простых шага» имеет несколько хороших иллюстраций и разбит на отдельные шаги.
«Анализ основных компонентов» из блога Джереми Куна — это приятная лаконичная статья, в которой есть ссылка на собственные лица.
Универсальный центр анализа основных компонентов от Мэтта Бремса.
Оригинал. Размещено с разрешения.
Как, где и когда следует использовать PCA | by Bartosz Szabłowski
Давайте рассчитаем ковариационную матрицу для нашего набора данных:
array ([[1.01010101, 0,97727597, -0,01747925, -0,04152546],
[0,97727597, 1,01010101, -0,039, -0,06169213],
[-0,01747925, -0,039, 1,01010101, 0,87546278] -01075139 -01516278] )
3. Собственное разложение.
· Собственные векторы ➞ направления PCA
· Собственные значения ➞ важность направлений
Ковариационная матрица симметрична, а собственные векторы симметричных матриц ортогональны. Таким образом, первый главный компонент объясняет большую часть дисперсии.Ортогонален ему второй главный компонент, который объясняет большую часть оставшейся дисперсии и так далее. Теперь пора выполнить разложение ковариационной матрицы.
собственные значения: [2.0243665 1,87865542 0,03358615 0,10379597]собственные векторы:
[[-0,62202904 -0,33364184 -0,69970849 -0,11032236]
[-0,6031108 -0,36974369 0,70534377 0,04513474]
[-0,32423873 0,63027923 0,09785443 -0,69859992]
[-0,37974529 0.59558444 - 0,05764294 0,70551399]]
Мы получили вектор (собственные значения), состоящий из 4 собственных значений и матрицы 4 × 4, хранящей собственные векторы.
4. Объяснение общей дисперсии.
Цель PCA — уменьшить количество измерений. Мы сжимаем текущие функции в новые функции, которые являются собственными векторами (главными компонентами), содержащими наибольшее количество информации. Информация эквивалентна дисперсии. Собственные значения — это размер собственных векторов. Следовательно, их следует расположить в порядке убывания. Объясняемый процент дисперсии — это собственное значение, деленное на общую сумму всех собственных значений. Исходя из этого, мы можем вычислить процент объясненной дисперсии для каждого главного компонента нашего набора:
[0.501, 0,465, 0,026, 0,008]
Как мы видим, сумма первых двух основных компонентов составляет более 95% дисперсии.
5. Преобразование признаков.
Мы преобразуем наш 4-мерный набор данных в сжатый 2-мерный набор данных. Используя первые два собственных вектора, мы создадим матрицу проекции и будем использовать ее для перемещения нашего набора данных в подпространство, состоящее из двух измерений.
Мы создаем пару кортежей собственных значений и собственных векторов, а затем сортируем их по убыванию собственных значений.Мы выбираем первые два собственных вектора, на которые приходится около 95% дисперсии. Мы создали матрицу проекции w , на которую мы перенесли наблюдения из набора данных. Наконец, мы визуализируем преобразованный набор данных.
Визуализация работы PCA, изображение автораПриведенный выше пример демонстрирует алгоритм PCA [ 3 ]. Теперь перейдем к практическому применению.
Мы больше не будем выполнять все шаги из алгоритма PCA, мы будем использовать его реализацию в scikit-learn.Мы познакомимся с популярным набором данных iris и посмотрим, поможет ли PCA улучшить классификацию.
Давайте загрузим данные и посмотрим первые 5 и последние 5 строк:
+ ----- + ----------- + ----------- + - ---------- + ----------- + ----------- +
| | sep_len | sep_wid | pet_len | pet_wid | виды |
| ----- + ----------- + ----------- + ----------- + ------ ----- + ----------- |
| 0 | 5.1 | 3.5 | 1.4 | 0,2 | сетоса |
| 1 | 4.9 | 3 | 1.4 | 0,2 | сетоса |
| 2 | 4.7 | 3.2 | 1.3 | 0,2 | сетоса |
| 3 | 4.6 | 3.1 | 1.5 | 0,2 | сетоса |
| 4 | 5 | 3.6 | 1.4 | 0,2 | сетоса |
| 145 | 6,7 | 3 | 5.2 | 2.3 | вирджиника |
| 146 | 6.3 | 2,5 | 5 | 1.9 | вирджиника |
| 147 | 6.5 | 3 | 5.2 | 2 | вирджиника |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | вирджиника |
| 149 | 5,9 | 3 | 5.1 | 1.8 | вирджиника |
+ ----- + ----------- + ----------- + ----------- + ------ ----- + ----------- +
Как видите, у нас есть четыре измерения, и каждому цветку присвоено название вида (вид в столбце). Всего цветов в базе 150. Давайте посчитаем базовую статистику для нашего набора данных:
+ ------- + ------------ + -------- ---- + ----------- + ------------ +
| | sep_len | sep_wid | pet_len | pet_wid |
| ------- + ------------ + ------------ + ----------- + - ---------- |
| счет | 150 | 150 | 150 | 150 |
| означает | 5.84333 | 3.05733 | 3.758 | 1.19933 |
| std | 0.828066 | 0.435866 | 1.7653 | 0.762238 |
| мин | 4.3 | 2 | 1 | 0,1 |
| 25% | 5.1 | 2,8 | 1.6 | 0,3 |
| 50% | 5.8 | 3 | 4.35 | 1.3 |
| 75% | 6.4 | 3.3 | 5.1 | 1.8 |
| макс | 7,9 | 4.4 | 6.9 | 2,5 |
+ ------- + ------------ + ------------ + ----------- + - ---------- +
virginica 50
setosa 50
versicolor 50
Имя: разновидности, dtype: int64
Конечно, в реальном проекте Data Science на этом этапе интеллектуальный анализ данных не должен заканчиваться, но в этой статье главный герой — PCA.Давайте попробуем визуализировать наши данные:
Визуализация набора данных Iris, изображение автора· Избавление от «избыточных» данных (коррелированные переменные)
Некоторые переменные несут схожую информацию. Посмотрим, так ли это в наших данных.
Pairplot, Image by AuthorКак видите, некоторые переменные коррелируют друг с другом, в первую очередь длина лепестка и ширина лепестка. Оба они также коррелируют с длиной чашелистника. Наименее полезной кажется ширина чашелистника. Можно сделать вывод, что с помощью только одной переменной разделить классы несложно, еще проще разделить классы по парам переменных.Теперь давайте проверим корреляции:
Коррелограмма набора данных радужки, изображение автораНаша предыдущая гипотеза подтвердилась, переменные длина чашелистика, длина лепестка и ширина лепестка сильно коррелированы друг с другом. В некоторых моделях машинного обучения коррелированные переменные ухудшают результат, поскольку они придают больший вес одному фрагменту информации. Пришло время применить PCA, но мы не сможем сделать это для всего набора данных, если позже построим модель для классификации видов. Если бы мы применили PCA ко всему набору данных, произошла бы утечка информации.Давайте создадим фрейм данных X, содержащий функции и вектор меток y, а затем разделим данные на обучающие и тестовые данные. Мы должны стандартизировать наш обучающий набор, как я писал ранее. Среднее значение будет равно 0 для каждой переменной, и данные будут в той же шкале — стандартное отклонение. После этой операции мы можем выполнить PCA на нашем наборе.
В обучающей выборке 100 строк.
Тестовый набор состоит из 50 рядов.
+ ----- + -------------- + ------------- + ------------- - + -------------- +
| | PC1 | PC2 | PC3 | PC4 |
| ----- + -------------- + ------------- + ------------- - + -------------- |
| PC1 | 1 | 6.45038e-17 | 2.13745e-17 | -4.80269e-17 |
| PC2 | 6.45038e-17 | 1 | 6.07219e-17 | 1.28115e-17 |
| PC3 | 2.13745e-17 | 6.07219e-17 | 1 | -5.57337e-17 |
| PC4 | -4.80269e-17 | 1.28115e-17 | -5.57337e-17 | 1 |
+ ----- + -------------- + ------------- + ------------- - + -------------- +
Как мы видим, переменные больше не коррелированы.
· Группировка признаков (функции представляют собой один фрагмент информации)
В некотором смысле это продолжение предыдущего раздела, поскольку коррелированные переменные несут одну часть информации.PCA — это не алгоритм, который объединяет наблюдения в кластеры, но вместо этого он может определить, какие функции в наименьшей степени способствуют объяснению структуры компонентов. Давайте теперь создадим распределение функций по компонентам. Чем больше вклад исходного элемента в компонент, тем темнее его цвет на графике.
Распределение функций по основным компонентам, изображение автораОтлично! Подтверждаем то, о чем вы читали ранее. Первый главный компонент был создан из коррелированных переменных.Второй главный компонент интересен тем, что мы не обнаружили значимой корреляции между длиной чашелистника и его шириной. Интересный.
· Уменьшение размеров без значительной потери информации
Объясненный график дисперсии показывает, сколько информации содержится в каждом основном компоненте. Мы можем использовать метод локтя, известный как выбор гиперпараметров в других моделях машинного обучения, чтобы выбрать подходящее количество компонентов. Еще одна форма визуализации — совокупный график.
Объясненная дисперсия и Кумулятивная объясненная дисперсия, Изображение автора+ ----------- + ---------------------- + - ----------------------------- +
| Компонент | Объясненное отклонение | Кумулятивная объясненная дисперсия |
+ ----------- + ---------------------- + ------------- ------------------ +
| 1 | 0.712014337051845000 | 0.7120143370518450 |
| 2 | 0.2396536428780 | 0.9516679799429029 |
| 3 | 0.043160458797882550 | 0.9948284387407854 |
| 4 | 0.005171561259214621 | 1.0000000000000000 |
+ ----------- + ---------------------- + ------------- ------------------ +
График показывает, что отклонение данных на 95% объясняется двумя компонентами.
· Визуализация многомерных данных
Мы живем в трехмерной реальности. Наш мозг очень хорошо это понимает. Однако все, что выходит за рамки трех измерений, нам обычно очень трудно представить.Используя методы уменьшения размерности, мы можем «сгладить» количество измерений нашего набора данных радужки и визуализировать его в двухмерном пространстве. В следующем примере представлена эта визуализация. Цвета точек на графике указывают на вид вида.
Как мы видим, сетоса хорошо отделена от других классов. Virginica и Versicolor имеют нечеткую границу, которая при разделении этих классов может снизить точность, но я не ошибаюсь, глядя на это двумерное представление данных.
· Часть процесса контролируемого обучения
Мы можем с уверенностью сказать, что 4-я промышленная революция — это время данных, которые нас окружают. Мы можем использовать PCA для сжатия данных, сделав наши алгоритмы машинного обучения «быстрее» и уменьшив набор данных. Меньшее количество входных переменных может привести к более простой модели прогнозирования, которая может иметь лучшую производительность при прогнозировании новых данных. Пришло время обучить нашу модель на обучающем наборе и проверить ее возможности на тестовом наборе. Применим логистическую регрессию! Мы обучим модель на исходном наборе, последовательно на стандартизированном наборе и всех основных компонентах.
+ ------------------------ + ---------- + ----------- ------------------- +
| Модель | Точность | Время обучения (микросекунды) |
+ ------------------------ + ---------- + ------------ ------------------ +
| немасштабированные данные | 1.0 | 48403 |
| масштабированные данные | 0,98 | 8973 |
| 4 основных компонента | 0,98 | 8977 |
| 3 основных компонента | 0,98 | 8008 |
| 2 основных компонента | 0.94 | 5985 |
| 1 Основные компоненты | 0,92 | 5983 |
+ ------------------------ + ---------- + ------------ ------------------ +
Набор данных Iris довольно мал по стандартам машинного обучения. Таким образом, разница в точности между 1,00 и 0,98 на тестовой выборке незначительна. Мы видим, что использование стандартизации оказывает большое влияние на время изучения модели. Если бы я внедрил модель в производство, это было бы 3 основных компонента, поскольку она уже имеет уменьшенную размерность, которая объясняет 0.99 дисперсии.
В этой статье я обсуждал применение PCA для уменьшения размерности, визуализации многомерных данных и его использование в обучении с учителем. Метод PCA может применяться только к числовым данным, как для анализа исходных данных, так и для уменьшения признаков (размеров). Это может помочь получить первые приблизительные очертания закономерностей, лежащих в основе данного явления. Он основан на корреляции, которая может вводить в заблуждение (помните: корреляция не подразумевает причинно-следственную связь!).Я надеюсь, что уменьшение размерности с помощью анализа главных компонентов теперь стало для вас более ясным. Другие используемые методы уменьшения размерности:
· ICA
· LLE
· ISOMAP
· t-SNE
. Если вам нужно что-то еще в этой статье, дайте мне знать, я отредактирую ее или вы хотите, чтобы я написал статью о конкретном алгоритме, дайте мне знать.
[ 1 ] Дж. Джеймс, Д. Виттен, Т. Хасти, Р. Тибширани, Введение в статистическое обучение: с приложениями в R (2013)
[ 2 ] A.Герон, Практическое машинное обучение с помощью Scikit ‑ Learn, Keras и TensorFlow (2017), O’Reilly Media
[ 3 ] С. Рашка, В. Мирджалили, Машинное обучение Python: машинное обучение и глубокое обучение с помощью Python , scikit-learn и TensorFlow 2, 2-е издание (2017 г.), Packt Publishing
обзор и последние разработки
(a) Анализ основных компонентов как исследовательский инструмент для анализа данных
Стандартный контекст для PCA как исследовательских данных инструмент анализа включает набор данных с наблюдениями на p числовых переменных для каждого из n юридических или физических лиц.Эти значения данных определяют p n -мерные векторы x 1 ,…, x p или, что то же самое, матрица данных n × p X , чей столбец j является вектором x j наблюдений над переменной j th. Ищем линейную комбинацию столбцов матрицы X с максимальной дисперсией. Такие линейные комбинации задаются формулой, где a — вектор констант a 1 , a 2 ,…, a p .Дисперсия любой такой линейной комбинации определяется как var ( X a ) = a ‘ S a , где S — это выборочная ковариационная матрица, связанная с набором данных, а’ обозначает транспонирование. Следовательно, определение линейной комбинации с максимальной дисперсией эквивалентно получению p -мерного вектора a , который максимизирует квадратичную форму a ‘ S a . Чтобы эта проблема имела четко определенное решение, необходимо наложить дополнительное ограничение, и наиболее распространенное ограничение связано с работой с векторами единичной нормы, т.е.е. требуя a ′ a = 1. Задача эквивалентна максимизации a ′ S a — λ ( a ′ a −1), где λ — множитель Лагранжа. Дифференцирование относительно вектора a и приравнивание к нулевому вектору дает уравнение
2,1
Таким образом, a должен быть (единичная норма) собственным вектором, а λ — соответствующим собственным значением ковариационной матрицы S .В частности, нас интересует наибольшее собственное значение , λ 1 (и соответствующий собственный вектор a 1 ), поскольку собственные значения представляют собой дисперсии линейных комбинаций, определяемых соответствующим собственным вектором a : var ( X a ) = a ′ S a = λ a ′ a = λ . Уравнение (2.1) остается в силе, если собственные векторы умножаются на -1, и поэтому знаки всех нагрузок (и оценок) являются произвольными, и только их относительные величины и образцы знаков имеют смысл.
Любая p × p вещественная симметричная матрица, такая как ковариационная матрица S , имеет ровно p вещественных собственных значений, λ k ( k = 1,…, p ), и их соответствующие собственные векторы могут быть определены для формирования ортонормированного набора векторов, то есть a ′ k a k ′ = 1, если k = k ′ и ноль иначе. Подход с использованием множителей Лагранжа с дополнительными ограничениями на ортогональность различных векторов коэффициентов также можно использовать, чтобы показать, что полный набор собственных векторов S является решением проблемы получения до p новых линейных комбинаций, которые последовательно максимизировать дисперсию с учетом некоррелированности с предыдущими линейными комбинациями [4].Некоррелированность возникает из-за того, что ковариация между двумя такими линейными комбинациями, X a k и X a k ′ , определяется как a ′ k ′ S a k = λ k a ′ k ′ a k = 0, если k ′ ≠ k .
Именно эти линейные комбинации X a k называются главными компонентами набора данных, хотя некоторые авторы по ошибке также используют термин «главные компоненты», когда ссылаются на собственные векторы a . к . В стандартной терминологии PCA элементы собственных векторов a k обычно называются загрузками ПК , тогда как элементы линейных комбинаций X a k называются ПК. набирает , так как это значения, которые каждый человек мог бы получить на данном ПК.
В стандартном подходе принято определять ПК как линейные комбинации центрированных переменных x * j , с общим элементом, где обозначает среднее значение наблюдений для переменной j . Это соглашение не меняет решения (кроме центрирования), поскольку ковариационная матрица набора центрированных или нецентрированных переменных одинакова, но имеет то преимущество, что обеспечивает прямую связь с альтернативным, более геометрическим подходом к PCA.
Обозначив X * матрицу n × p , столбцы которой являются центрированными переменными x * j , мы имеем
2,2
Уравнение (2.2) связывает собственное разложение ковариационной матрицы S с разложением по сингулярным значениям матрицы данных с центром по столбцам X *. Любая произвольная матрица Y размерности n × p и ранга r (обязательно) может быть записана (e.г. [4]) как
2.3
где U , A — это матрицы n × r и p × r с ортонормированными столбцами ( U ′ U = I r = A ′ A , с I r единичная матрица r × r ) и L — это диагональная матрица r × r . Столбцы A называются правыми сингулярными векторами Y и являются собственными векторами матрицы p × p Y ‘ Y , связанной с ее ненулевыми собственными значениями.Столбцы U называются левыми сингулярными векторами Y и являются собственными векторами матрицы n × n Y Y ‘, которые соответствуют ее ненулевым собственным значениям. Диагональные элементы матрицы L называются сингулярными значениями Y и являются неотрицательными квадратными корнями из (общих) ненулевых собственных значений как матрицы Y ′ Y , так и матрицы Y Y ′. Мы предполагаем, что диагональные элементы L расположены в порядке убывания, и это однозначно определяет порядок столбцов U и A (за исключением случая одинаковых сингулярных значений [4]).Следовательно, принимая Y = X *, правые сингулярные векторы матрицы данных с центром в столбцах X * являются векторами a k загрузок ПК. Из-за ортогональности столбцов A , столбцы матричного продукта X * A = ULA ′ A = UL являются ПК X *. Дисперсии этих ПК представлены квадратами сингулярных значений X *, деленных на n -1.Эквивалентно, учитывая (2.2) и указанные выше свойства,
2,4
, где L 2 — диагональная матрица с возведенными в квадрат сингулярными значениями (т. Е. Собственными значениями ( n -1) S ). Уравнение (2.4) дает спектральное разложение или собственное разложение матрицы ( n -1) S . Следовательно, PCA эквивалентен SVD матрицы данных с центром по столбцам X *.
Свойства SVD предполагают интересные геометрические интерпретации PCA.Для любого ранга r матрица Y размером n × p , матрица Y q того же размера, но ранга q < r , элементы которой минимизируют сумма квадратов разностей с соответствующими элементами Y дается [7] как
2,5
где L q — диагональная матрица q × q с первым (наибольшим) q диагональные элементы L и U q , A q — это матрицы n × q и p × q , полученные путем сохранения соответствующих столбцов q в U и A .
В нашем контексте n строк ранга r столбцовой матрицы данных X * определяют диаграмму рассеяния n точек в r -мерном подпространстве, с центром в центре силы тяжести диаграммы рассеяния. Приведенный выше результат подразумевает, что « наилучшее » приближение n точек к этой диаграмме рассеяния в подпространстве размерности q задается строками X * q , определенными как в уравнении (2 .5), где «лучший» означает, что сумма квадратов расстояний между соответствующими точками на каждой диаграмме рассеяния минимизирована, как в оригинальном подходе Пирсона [1]. Система осей q в этом представлении задается первыми ПК q и определяет главное подпространство . Следовательно, PCA — это, по сути, метод уменьшения размерности, посредством которого набор исходных переменных p может быть заменен оптимальным набором производных переменных q , ПК.Когда q = 2 или q = 3, возможна графическая аппроксимация диаграммы рассеяния n точек, которая часто используется для начального визуального представления полного набора данных. Важно отметить, что этот результат является инкрементным (следовательно, адаптивным) по своим размерам в том смысле, что лучшее подпространство размерности q +1 получается путем добавления дополнительного столбца координат к тем, которые определяли наилучшие q -мерное решение.
Качество любой аппроксимации размеров q можно измерить по изменчивости, связанной с набором сохраненных ПК.Фактически, сумма дисперсий исходных переменных p является следом (суммой диагональных элементов) ковариационной матрицы S . Используя результаты простой теории матриц, легко показать, что это значение также является суммой дисперсий всех p ПК. Следовательно, стандартным показателем качества данного ПК является доля от общей дисперсии , которую он составляет,
2,6
где tr ( S ) обозначает след S .Инкрементальный характер ПК также означает, что мы можем говорить о доле общей дисперсии, объясняемой набором ПК (обычно, но не обязательно, первые на ПК), которая часто выражается как процента от общей дисперсии. приходилось: .
Обычной практикой является использование некоторого предопределенного процента от общей дисперсии, объясненной, чтобы решить, сколько ПК должно быть сохранено (70% общей изменчивости является общей, если субъективной, точкой отсечения), хотя требования графического представления часто приводят к к использованию только первых двух или трех ПК.Даже в таких ситуациях процент от общей учтенной дисперсии является фундаментальным инструментом для оценки качества этих низкоразмерных графических представлений набора данных. Акцент в PCA почти всегда делается на первых нескольких ПК, но есть обстоятельства, в которых последние несколько могут представлять интерес, например, при обнаружении выбросов [4] или некоторых приложениях анализа изображений (см. §3c).
ПКтакже могут быть предложены как оптимальное решение множества других проблем. Критерии оптимальности для PCA подробно обсуждаются в многочисленных источниках (см., Среди прочего, [4,8,9]).МакКейб [10] использует некоторые из этих критериев для выбора оптимальных подмножеств исходных переменных, которые он называет главными переменными . Это другая, более сложная в вычислительном отношении проблема [11].
(b) Пример: данные по ископаемым зубам
PCA был применен и признан полезным во многих дисциплинах. Два примера, рассмотренные здесь и в § 3b, очень различаются по своей природе. В первом изучается набор данных, состоящий из девяти измерений 88 ископаемых зубов раннего насекомоядного млекопитающего Kuehneotherium, а второй, в § 3b, взят из атмосферных наук.
Kuehneotherium — одно из самых ранних млекопитающих, останки которого были обнаружены во время добычи известняка в Южном Уэльсе, Великобритания [12]. Кости и зубы были вымыты в трещины в скале около 200 миллионов лет назад, и все нижние коренные зубы, использованные в этом анализе, взяты из одной трещины. Однако казалось возможным, что в образце присутствовали зубы более чем одного вида Kuehneotherium.
Из девяти переменных три измеряют длину зуба, а остальные шесть измеряют высоту и ширину.PCA был выполнен с использованием команды prcomp статистической программы R [13]. На первые два ПК приходится 78,8% и 16,7%, соответственно, от общего разброса в наборе данных, поэтому двумерная диаграмма рассеяния для 88 зубов, представленная на рисунке, является очень хорошим приближением к исходной диаграмме рассеяния для девяти зубов. пространственное пространство. Это, по определению, лучший двумерный график данных с сохранением дисперсии, представляющий более 95% общей вариации. Все загрузки на первом ПК имеют один и тот же знак, поэтому это средневзвешенное значение всех переменных, представляющее «общий размер».В России большие зубы находятся слева, а маленькие — справа. Второй ПК имеет отрицательные нагрузки для трех переменных длины и положительные нагрузки для других шести переменных, что представляет собой аспект «формы» зубов. Окаменелости в верхней части имеют меньшую длину по сравнению с их высотой и шириной, чем в нижней части. Относительно компактный кластер точек в нижней половине, как полагают, соответствует виду Kuehneotherium, в то время как более широкая группа вверху не может быть отнесена к Kuehneotherium, а к некоторым родственным, но еще не идентифицированным животным.
Двумерное главное подпространство для данных ископаемых зубов. Координаты на одном или обоих компьютерах могут переключать знаки при использовании другого программного обеспечения.
(c) Некоторые ключевые вопросы
(i) Ковариация и анализ главных компонентов корреляционной матрицы
До сих пор ПК были представлены как линейные комбинации (центрированных) исходных переменных. Однако свойства PCA имеют некоторые нежелательные особенности, когда эти переменные имеют разные единицы измерения.Хотя со строго математической точки зрения нет ничего принципиально неправильного в линейных комбинациях переменных с разными единицами измерения (их использование широко распространено, например, в линейной регрессии), тот факт, что PCA определяется критерием (дисперсия ), который зависит от единиц измерения, подразумевает, что ПК, основанные на ковариационной матрице S , изменятся, если единицы измерения одной или нескольких переменных изменятся (если только не все Переменные p претерпевают общее изменение масштаба , и в этом случае новая ковариационная матрица является просто скалярным кратным старой, следовательно, с теми же собственными векторами и той же долей общей дисперсии, объясняемой каждым ПК).Чтобы преодолеть эту нежелательную особенность, обычно начинают со стандартизации переменных. Каждое значение данных x ij центрируется и делится на стандартное отклонение s j наблюдений n переменной j ,
2,7
Таким образом, матрица исходных данных X заменяется стандартизированной матрицей данных Z , у которой j -й столбец является вектором z j с n стандартизированными наблюдениями переменной. j (2.7). Стандартизация полезна, потому что большинство изменений масштаба — это линейные преобразования данных, которые используют один и тот же набор стандартизованных значений данных.
Поскольку ковариационная матрица стандартизованного набора данных является просто корреляционной матрицей R исходного набора данных, PCA стандартизированных данных также известен как PCA корреляционной матрицы. Собственные векторы a k корреляционной матрицы R определяют некоррелированные линейные комбинации максимальной дисперсии стандартизованных переменных z 1 ,…, z p .Такие ПК с корреляционной матрицей не идентичны и не связаны напрямую с ранее определенными ПК ковариационной матрицы . Кроме того, процентное отклонение, учитываемое каждым ПК, будет отличаться, и довольно часто требуется больше ПК корреляционной матрицы, чем ПК ковариационной матрицы, чтобы учесть один и тот же процент от общей дисперсии. След корреляционной матрицы R — это просто число p переменных, используемых в анализе, следовательно, доля общей дисперсии, приходящаяся на любую корреляционную матрицу PC, представляет собой просто дисперсию этого PC, деленную на p .Подход SVD также применим в этом контексте. Поскольку ( n -1) R = Z ′ Z , SVD стандартизованной матрицы данных Z составляет PCA корреляционной матрицы набора данных в соответствии с линиями, описанными после уравнения (2.2).
ПК с корреляционной матрицей инвариантны к линейным изменениям единиц измерения и, следовательно, являются подходящим выбором для наборов данных, где для каждой переменной возможны различные изменения масштаба.Некоторое статистическое программное обеспечение по умолчанию предполагает, что PCA означает PCA корреляционной матрицы и, в некоторых случаях, нормализация, используемая для векторов нагрузок a k ПК с корреляционной матрицей, не является стандартной a ′ k a k = 1. В корреляционной матрице PCA коэффициент корреляции между j -й переменной и k -й PC равен (см. [4])
2.8
Таким образом, если нормализация используется вместо a ′ k a = 1, коэффициенты новых векторов нагрузки являются корреляциями между каждой исходной переменной и k -м ПК.
В данных по ископаемым зубам в § 2b все девять измерений даны в одних и тех же единицах, поэтому ковариационная матрица PCA имеет смысл. Корреляционная матрица PCA дает аналогичные результаты, поскольку дисперсии исходной переменной не сильно различаются.На первые две корреляционные матрицы ПК приходится 93,7% общей дисперсии. Для других наборов данных различия могут быть более существенными.
(ii) Двойные графики
Одно из наиболее информативных графических представлений многомерного набора данных — это двоичный график [14], который фундаментально связан с SVD соответствующей матрицы данных и, следовательно, с PCA. Ранг q приближение X * q полной матрицы данных с центрированием по столбцам X *, определенной формулой (2.5), записывается как X * q = GH ′, где G = U q и H = A q L q (хотя возможны и другие варианты, см. [4]). n строк g i матрицы G определяют графические маркеры для каждого человека, которые обычно представлены точками. Строки p h j матрицы H определяют маркеры для каждой переменной и обычно представлены векторами.Свойства двумерного графика лучше всего обсуждать, предполагая, что q = p , хотя двунаправленный график определяется на приближении низкого ранга (обычно q = 2), что позволяет графическое представление маркеров. Когда q = p двумерный график имеет следующие свойства:
— Косинус угла между любыми двумя векторами, представляющими переменные, является коэффициентом корреляции между этими переменными; это прямой результат того факта, что матрица внутренних продуктов между этими маркерами составляет HH ′ = AL 2 A ′ = ( n −1) S (2.4), так что скалярные произведения между векторами пропорциональны ковариациям (дисперсиям для общего вектора).
— Точно так же косинус угла между любым вектором, представляющим переменную, и осью, представляющей данный ПК, является коэффициентом корреляции между этими двумя переменными.
— Внутреннее произведение между маркерами для индивидуального i и переменной j дает (центрированное) значение индивидуального i для переменной j .Это прямой результат того факта, что GH ′ = X *. Практическое значение этого результата состоит в том, что ортогональное проецирование точки, представляющей индивидуальные i , на вектор, представляющий переменную j , восстанавливает (центрированное) значение.
— Евклидово расстояние между маркерами для индивидов i и i ′ пропорционально расстоянию Махаланобиса между ними (подробнее см. [4]).
Как указано выше, эти результаты являются точными только в том случае, если используются все размеры q = p .Для q < p результаты являются лишь приблизительными, и общее качество таких приближений можно измерить процентным соотношением дисперсии, объясняемой ПК с наибольшей дисперсией q , которые использовались для построения матриц маркеров G и H .
дает двумерный график для корреляционной матрицы PCA данных ископаемых зубов из § 2b. Маркеры переменных отображаются в виде стрелок, а маркеры зубов — в виде чисел. Группа из трех почти горизонтальных и очень тесно связанных переменных-маркеров для двух переменных ширины и одной переменной высоты, WIDTH , HTMDT и TRIWIDTH , предлагает группу сильно коррелированных переменных, которые также сильно коррелированы с первым ПК. (представлен горизонтальной осью).Очень высокая доля изменчивости, объясняемая двумерным главным подпространством, дает веские основания для этих выводов. Фактически, наименьший из трех истинных коэффициентов корреляции между этими тремя переменными составляет 0,944 ( HTMDT и TRIWIDTH ), а наименьшая корреляция между PC1 и любой из этих переменных составляет 0,960 ( TRIWIDTH ). Разница знаков в нагрузках PC2 между тремя переменными длины (в нижнем левом углу графика) и другими переменными четко видна.Проецирование маркера для индивидуума 58 на положительные направления всех переменных маркеров предполагает, что ископаемый зуб 58 (слева от двунаправленной диаграммы) является большим зубом. Проверка матрицы данных подтверждает, что это самый крупный индивид по шести из девяти переменных и близкий к самому большому по оставшимся трем. Точно так же у людей 85–88 (справа) зубы небольшого размера. Лица, маркеры которых близки к исходной точке, имеют значения, близкие к среднему для всех переменных.
Биплот для данных ископаемых зубов (корреляционная матрица PCA), полученный с помощью команды R’s biplot .(Онлайн-версия в цвете.)
(iii) Центры
Как было показано в § 2, PCA представляет собой SVD матрицы данных с центром в столбцах. В некоторых приложениях [15] центрирование столбцов матрицы данных может считаться неуместным. В таких ситуациях может быть предпочтительным избежать любой предварительной обработки данных и подвергнуть матрицу нецентрированных данных SVD или, что эквивалентно, выполнить собственное разложение матрицы нецентрированных секундных моментов, T , чьи собственные векторы определяют линейные комбинации нецентрированных переменных.Его часто называют нецентрированным PCA , и в некоторых областях была неудачная тенденция приравнивать имя SVD только к этой нецентрированной версии PCA.
Нецентральные ПК представляют собой линейные комбинации нецентральных переменных, которые последовательно максимизируют нецентральные вторые моменты, при условии, что их пересекающиеся нецентральные вторые моменты равны нулю. За исключением случаев, когда средний вектор столбца (т.е. центр тяжести исходной диаграммы рассеяния n точек в пространстве p ) близок к нулю (в этом случае центрированный и нецентрированный моменты подобны), это не сразу интуитивно понятно. что между обоими вариантами PCA должно быть сходство.Cadima и Jolliffe [15] исследовали отношения между стандартным (центрированным по столбцам) PCA и нецентрированным PCA и обнаружили, что они ближе, чем можно было ожидать, в частности, когда размер вектора большой. Часто бывает, что существует большое сходство между многими собственными векторами и (абсолютными) собственными значениями ковариационной матрицы S и соответствующей матрицы нецентрированных вторых моментов, T .
В некоторых приложениях подходящим считалось центрирование строк или центрирование строк и столбцов (известное как двойное центрирование) матрицы данных.SVD таких матриц приводят к центрированным строкам и дважды центрированным PCA , соответственно.
(iv) Когда
n < pНаборы данных, в которых наблюдаемых объектов меньше, чем переменных ( n < p ), становятся все более частыми благодаря растущей простоте наблюдения за переменными вместе с высокая стоимость повторения наблюдений в некоторых контекстах (например, на микрочипах [16]). Например, в [17] есть пример из геномики, в котором n = 59 и p = 21 225.
В общем, ранг матрицы данных n × p равен. Если матрица данных центрирована по столбцам, то это так. Когда n < p , то количество наблюдаемых индивидов, а не количество переменных, обычно определяет ранг матрицы. Ранг матрицы данных с центрированием по столбцам X * (или ее стандартизованного аналога Z ) должен равняться рангу ковариационной (или корреляционной) матрицы. Практическое значение этого состоит в том, что имеется только — ненулевых собственных значений; следовательно, r ПК объясняют всю изменчивость набора данных.Ничто не препятствует использованию PCA в таких контекстах, хотя некоторое программное обеспечение, как в случае с командой R princomp (но не prcomp ), может препятствовать использованию таких наборов данных. PC могут быть определены как обычно, либо с помощью SVD (центрированной) матрицы данных, либо с помощью собственных векторов / значений ковариационной (или корреляционной) матрицы.
Недавнее исследование (например, [18,19]) изучило, насколько хорошо базовые «популяционные» ПК оцениваются выбранными ПК в случае, когда n ≪ p , и показано, что в некоторых обстоятельствах сходство между выборочными и популяционными ПК.Однако результаты обычно основаны на модели данных, которая имеет очень небольшое количество структурированных компьютеров и очень много измерений шума, и которая имеет некоторые связи с недавней работой в RPCA (см. §3c).
en: pca [Анализ данных по экологии сообществ в R]
Раздел: Анализ рукоположения
PCA и tb-PCA (линейная неограниченная ординация)
Теория R функции Примеры
Анализ главных компонентов ( PCA ) — это линейный метод неограниченного ординации.Он неявно основан на евклидовых расстояниях между выборками, что связано с проблемой двойного нуля. Таким образом, PCA не подходит для разнородных наборов композиционных данных с большим количеством нулей (так часто бывает в наборах экологических данных, в которых многие виды отсутствуют во многих выборках). Его можно применять к количественным переменным (они также могут быть отрицательными), а также к данным о присутствии-отсутствии, но он не может обрабатывать качественные переменные. Анализ главных компонентов на основе преобразования ( tb-PCA ) — это PCA, применяемый к предварительно преобразованным данным видового состава (с использованием e.г. Hellinger, chord или другое преобразование) и неявно основывается на расстоянии, отличном от евклидова (Hellinger, chord или другое), что невосприимчиво к проблеме двойного нуля.
Упрощенное описание алгоритма PCA
(a) Используйте матрицу образцов × видов (или, как правило, образцов × дескрипторов, где дескрипторы могут быть также переменными окружающей среды), и отобразите каждый образец в многомерном пространстве, где каждое измерение определяется численностью одного вида ( или дескриптор).Таким образом, образцы будут создавать облако, расположенное в многомерном пространстве.
(b) Вычислите центр тяжести облака.
(c) Переместите центры осей к этому центроиду.
(d) Поверните оси таким образом, чтобы первая ось проходила через облако в направлении наибольшего отклонения; позиции выборок на этой оси становятся баллами выборки . Вторая ось построена таким образом, чтобы быть перпендикулярной первой оси, что означает, что корреляция оценок выборки на первой оси и оценок выборки на второй оси равна нулю.Если можно построить больше осей (что не относится к этому примеру, поскольку исходное пространство, определяемое двумя видами, является только двумерным), то каждая высшая ось ординации перпендикулярна всем предыдущим).
Рис. 1 (из Legendre & Legendre 1998) иллюстрирует этот алгоритм на очень простом случае только с двумя видами (дескрипторами) и пятью образцами. Рис. 2 иллюстрирует ту же логику в облаке данных в трехмерном пространстве (три вида / дескриптора).
Рисунок 1: Ординация PCA пяти образцов и двух видов.(Рис. 9.2 из Legendre & Legendre 1998.) Рисунок 2: 3D-схема алгоритма ординации PCA
Важные выходные данные для рассмотрения
Собственные значения отдельных осей, которые представляют величину отклонения, которое данная ось представляет от общего отклонения (общая инерция). Можно вычислить долю дисперсии, объясняемую данной осью, как собственное значение оси, деленное на общую дисперсию. Если несколько основных осей объясняют большую часть дисперсии, ординация была успешной (многомерная информация была успешно сокращена до нескольких основных измерений).Вы можете построить гистограмму с каждым собственным значением в виде столбца, чтобы увидеть, насколько стабильно / резко уменьшаются собственные значения более высоких осей.
Оценка образцов и участков по осям ординации (эта информация затем используется для построения диаграммы ординации). Каждая ось PCA представляет собой линейную комбинацию всех дескрипторов.
Факторные нагрузки, также известные как нагрузки компонентов — корреляция переменной (разновидностей или общих дескрипторов) с отдельными осями PCA. При стандартизации факторные нагрузки можно сравнивать между переменными и помогать интерпретировать, какие дескрипторы в основном связаны с какой осью PCA.
Корреляция между переменными описывается углами между векторами переменных, а не расстоянием между вершинами векторов. Это верно только в том случае, если масштабирование диаграммы ординации установлено на 2 (биплот корреляции; см. Примечание о масштабировании ниже).
Основное применение PCA для экологических данных
При рассмотрении экологических данных PCA имеет три основных применения:
1) Опишите структуру корреляции между различными переменными , e.г. переменные окружающей среды, измеренные для каждого образца, или видовые характеристики (признаки), измеренные для отдельных видов. В этом случае переменные необходимо стандартизировать до нулевого среднего и единичного стандартного отклонения, в противном случае переменная с более высокими абсолютными значениями или дисперсией будет более важной в анализе. Полученное в результате ординация PCA может показать основные параметры вариации данных. Эта информация может быть дополнительно обработана несколькими способами:
Используйте выборочные оценки на осях PCA в качестве «сложных» переменных, представляющих несколько реальных переменных, тесно связанных с ними, и используйте набор из нескольких PCA в дальнейшем анализе вместо многих реальных (и, возможно, сильно коррелированных переменных).
Используйте несколько основных осей PCA и из реальных переменных выберите одну, наиболее коррелирующую с каждой осью PCA; Таким образом, мы можем сократить большое количество (часто сильно коррелированных) переменных до нескольких с возможно низкой корреляцией (оси PCA по определению не коррелированы друг с другом).
Группы сильно коррелированных переменных могут быть получены путем кластеризации, примененной к матрице корреляции между переменными, преобразованными в расстояния (либо как D = 1 — cor (var), либо D = 1 — abs (cor (var))).
2) Анализ данных относительно однородного видового состава . «Относительно однородный» означает, что в этих данных мы предполагаем, что реакция вида вдоль (гипотетического) градиента среды может быть описана линейной зависимостью. Такие данные должны содержать небольшое количество нулей, что снижает проблему проблемы двойного нуля, к которой чувствительно евклидово расстояние (см. Экологическое сходство> Индексы расстояния> Евклидово расстояние). При применении к разнородному набору данных с большим количеством нулей результат часто показывает сильный подковообразный артефакт, когда участки, не имеющие общих видов, появляются очень близко друг к другу на диаграмме ординации.
3) Относительно недавно было высказано предположение, что PCA, примененный к предварительно преобразованным данным видового состава (например, с помощью преобразования Хеллингера), может решить проблему евклидовых расстояний в PCA и двойных нулях. В случае преобразования Хеллингера евклидово расстояние (неявно для PCA), примененное к преобразованным по Хеллингеру необработанным данным видового состава, приводит к PCA, представляющему расстояния Хеллингера между образцами, на которые не влияет проблема двойного нуля. Этот метод называется PCA на основе преобразования (tb-PCA) и описывается в отдельном разделе.Обратите внимание, однако, что не все согласны с тем, что это хорошая идея (см. Презентацию Питера Минчина и Лорен Ренни на ESA 2010 по этой теме).
Что означает масштабирование в двоичном графике ординации PCA?
Не существует единого способа отображения участков и переменных (видов) на одной и той же двумерной диаграмме (т.е. на диаграмме, показывающей два типа результатов, здесь узлы и переменные), поэтому есть два способа масштабирования результатов 1) :
- Масштабирование 1 — расстояния между объектами (точками) на двумерном графике являются приближениями их евклидовых расстояний в многомерном пространстве; углы между векторами дескрипторов (видов) не имеют смысла. Выберите это масштабирование, если основной интерес представляет интерпретация отношений между объектами (рис. 3 слева).
- Масштаб 2 — расстояния между объектами на двумерном графике не являются приближениями их евклидовых расстояний; углы между векторами дескрипторов (видов) отражают их корреляции. Выберите это масштабирование, если основной интерес сосредоточен на отношениях между дескрипторами (видами) (рис. 3 справа).
Рисунок 3: Диаграммы порядка расположения PCA, рассчитанные на основе логарифмически преобразованных данных о пастбищах.На диаграмме слева используется масштабирование = 1 с фокусом на выборках, а на правой диаграмме используется масштабирование = 2 с акцентом на переменные / виды.
Круг равновесного вклада
Круг иногда проецируется на диаграмму ординации, чтобы оценить важность отдельных видов / дескрипторов / переменных. Радиус рассчитывается как √ ( d / p ), где d — это количество отображаемых осей PCA (обычно d = 2), а p — количество переменных (столбцов в наборе данных). .Дескриптор с вектором той же длины, что и радиус окружности, вносит равный вклад во все оси в PCA; векторы, увеличивающие радиус круга, вносят больший вклад, чем средний в текущее отображение, и могут быть интерпретированы с уверенностью (в контексте данного количества осей ординации, здесь два, рис. 4).
Рисунок 4: Круг равновесного вклада, спроецированный на диаграмму ординации PCA. PCA на основе набора данных химического состава водно-болотных угодий.
Использование анализа главных компонентов (PCA) для проводника данных.Шаг за шагом
Когда мы работаем с машинным обучением для анализа данных, мы часто сталкиваемся с огромными наборами данных, которые обладают сотнями или тысячами различных функций или переменных. Как следствие, размер пространства переменных значительно увеличивается, что затрудняет анализ данных для получения выводов. Для решения этой проблемы удобно уменьшить количество переменных таким образом, чтобы с меньшим количеством переменных мы по-прежнему могли охватить большую часть информации, необходимой для анализа данных.
Простой способ уменьшить размерность пространства переменных — это применить некоторые методы матричной факторизации. Математические методы факторизации матриц имеют множество приложений в различных задачах, связанных с искусственным интеллектом, поскольку уменьшение размерности является сутью познания.
В этой статье мы показываем на некоторых игрушечных примерах, как использовать методы матричной факторизации для анализа многомерных наборов данных, чтобы получить из них некоторые выводы, которые могут помочь нам в принятии решений.В частности, мы объясняем, как использовать метод анализа главных компонентов (PCA) для уменьшения размерности пространства переменных.
В этой статье рассматриваются основные концепции PCA и то, как этот метод может быть применен в качестве полезного инструмента для анализа многомерных данных. Тем не менее, мы хотели бы подчеркнуть, что в этой статье мы не собираемся строго разрабатывать математические методы, используемые для PCA. Предполагается, что читатели должны понимать все концепции и процедуры, связанные с этим методом.
Что такое анализ главных компонентов (PCA)?
Анализ главных компонентов (PCA) — это статистическая процедура, которая использует ортогональное преобразование для преобразования набора наблюдений возможно коррелированных переменных в набор значений линейно некоррелированных переменных, называемых главными компонентами (или иногда, главными модами вариации).
PCA используется почти во всех научных дисциплинах и, вероятно, представляет собой самый популярный метод многомерной статистики.PCA применяется к таблице данных, представляющей наблюдения, описанные несколькими зависимыми переменными, которые, как правило, взаимосвязаны. Цель состоит в том, чтобы извлечь соответствующую информацию из таблицы данных и выразить эту информацию в виде набора новых ортогональных переменных. PCA также представляет образец сходства в наблюдениях и переменных, отображая их в виде точек на картах (см. Ссылки Jolliffe I.T., Jackson J.E, Saporta G, Niang N. для получения более подробной информации).
Количество главных компонентов меньше или равно количеству исходных переменных или количеству наблюдений.Это преобразование определяется таким образом, что первый главный компонент имеет максимально возможную дисперсию (т. Е. Учитывает как можно большую вариативность данных), а каждый последующий компонент, в свою очередь, имеет максимальную дисперсию, возможную при ограничении что он ортогонален предыдущим компонентам. Результирующие векторы образуют некоррелированный ортогональный базисный набор (подробнее см. Ссылку)
PCA в основном используется в качестве инструмента для исследовательского анализа данных и для создания прогнозных моделей.PCA может выполняться путем разложения по собственным значениям ковариационной (или корреляционной) матрицы данных или разложения по сингулярным значениям матрицы данных, обычно после центрирования по среднему (и нормализации или использования Z-показателей) матрицы данных для каждого атрибута (см. Ссылку Abdi. H ., И Уильямс, Л.Дж.). Результаты PCA обычно обсуждаются в терминах оценок компонентов, иногда называемых факторными оценками (преобразованные значения переменных, соответствующих конкретной точке данных), и нагрузок (вес, на который следует умножить каждую стандартизованную исходную переменную, чтобы получить оценку компонента. ) (см. ссылку Шоу П.J.A. )
Вкратце, мы можем сказать, что PCA является самым простым из многомерного анализа на основе собственных векторов, и его часто используют в качестве метода для выявления внутренней структуры данных таким образом, чтобы лучше всего объясняла их дисперсию. Ниже приведены некоторые цели метода PCA:
- Уменьшение размерности.
- Определение линейных комбинаций переменных.
- Выбор характеристик или возможностей: выбор наиболее полезных переменных.
- Визуализация многомерных данных.
- Идентификация основных переменных.
- Идентификация групп объектов или выбросов.
Теперь на игрушечном примере мы подробно и шаг за шагом опишем, как сделать PCA. После этого мы покажем, как использовать библиотеку [scikit -learn] в качестве ярлыка для той же процедуры анализа данных.
Подготовка набора данных Iris в качестве первого примера
Об Ирис
В следующем примере мы будем работать со знаменитым набором данных Iris, который был размещен в репозитории машинного обучения UCI (https: // archive.ics.uci.edu/ml/datasets/Iris).
Набор данных ириса содержит измерения для 150 цветков ириса трех разных видов.
Три класса в наборе данных Iris:
- Ирис сетоса (n = 50)
- Ирис разноцветный (n = 50)
- Ирис вирджинский (n = 50)
И четыре характеристики в наборе данных Iris:
- длина чашелистика в см
- ширина чашелистика, см
- длина лепестка в см
- ширина лепестка в см
Краткое изложение подхода PCA
- Стандартизируйте данные.
- Получите собственные векторы и собственные значения из ковариационной матрицы или корреляционной матрицы.
- Сортировка собственных значений в порядке убывания и выбор $ k $ собственных векторов, соответствующих $ k $ наибольшим собственным значениям, где $ k $ — количество измерений подпространства новых признаков ($ k \ le d $).
- Постройте матрицу проекции $ \ mathbf {W} $ из выбранных $ k $ собственных векторов.
- Преобразуйте исходный набор данных $ \ mathbf {X} $ с помощью $ \ mathbf {W} $, чтобы получить $ k $ -мерное подпространство признаков $ \ mathbf {Y} $.
Загрузка набора данных
Чтобы загрузить данные Iris непосредственно из репозитория UCI, мы собираемся использовать превосходную библиотеку pandas. Если вы еще не использовали pandas, я хочу посоветовать вам ознакомиться с руководствами по pandas. Если бы мне пришлось назвать одну библиотеку Python, которая делает работу с данными удивительно простой задачей, это определенно были бы pandas!
импортировать панд как pd
df = pd.read_csv (
filepath_or_buffer = 'https: //archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.данные',
заголовок = Нет,
sep = ',')
df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'класс']
df.dropna (how = "all", inplace = True) # удаляет пустую строку в конце файла
df.tail () Разделить таблицу данных на данные X и метки классов y
X = df.ix [:, 0: 4] .values
y = df.ix [:, 4] .values Наш набор данных радужной оболочки теперь хранится в форме матрицы размером $ 150 \ times 4 $, в которой столбцы представляют собой различные характеристики, а каждая строка представляет собой отдельный образец цветка.T} = \ begin {pmatrix} x_1 \ newline x_2 \ newline x_3 \ newline x_4 \ end {pmatrix} = \ begin {pmatrix} \ text {длина чашелистика} \ newline \ text {ширина чашелистика} \ newline \ text {длина лепестка} \ newline \ text {ширина лепестка} \ end {pmatrix} $
Исследовательская визуализация
Чтобы получить представление о том, как 3 разных класса цветов распределены по 4 различным объектам, позвольте нам визуализировать их с помощью гистограмм.
из matplotlib import pyplot as plt
импортировать numpy как np
импортная математика
label_dict = {1: 'Ирис-Сетоса',
2: 'Ирис-разноцветный',
3: 'Ирис-Виргника'}
feature_dict = {0: 'длина чашелистика [см]',
1: 'ширина чашелистника [см]',
2: 'длина лепестка [см]',
3: 'ширина лепестка [см]'}
с plt.style.context ('seaborn-whitegrid'):
plt.figure (figsize = (8, 6))
для cnt в диапазоне (4):
plt.subplot (2, 2, cnt + 1)
для лаборатории в ('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'):
plt.hist (X [y == lab, cnt],
label = lab,
бункеры = 10,
альфа = 0,3,)
plt.xlabel (feature_dict [cnt])
plt.legend (loc = 'верхний правый', fancybox = True, fontsize = 8)
plt.tight_layout ()
plt.savefig ('PREDI.png', format = 'png', dpi = 1200)
plt.показать () Стандартизация данных
Следует ли стандартизировать данные перед PCA по ковариационной матрице, зависит от шкалы измерений исходных функций. Поскольку PCA дает подпространство признаков, которое максимизирует дисперсию по осям, имеет смысл стандартизировать данные, особенно если они были измерены в разных масштабах. Хотя все функции в наборе данных Iris были измерены в сантиметрах, давайте продолжим преобразование данных в единичную шкалу (среднее значение = 0 и дисперсия = 1), что является требованием для оптимальной производительности многих алгоритмов машинного обучения.Для стандартизации данных мы можем использовать библиотеку scikit learn.
из sklearn.preprocessing import StandardScaler
X_std = StandardScaler (). Fit_transform (X) 1 — Собственное разложение — Вычисление собственных векторов и собственных значений
Собственные векторы и собственные значения ковариационной (или корреляционной) матрицы представляют собой «ядро» PCA: собственные векторы (главные компоненты) определяют направления нового пространства признаков, а собственные значения определяют их величину.n x_ {i}.
долларов СШАВектор среднего — это $ d $ -мерный вектор, где каждое значение в этом векторе представляет собой выборочное среднее значение столбца признаков в наборе данных.
с номером:
импортировать numpy как np
mean_vec = np.mean (X_std, ось = 0)
cov_mat = (X_std - mean_vec) .T.dot ((X_std - mean_vec)) / (X_std.shape [0] -1)
print ('Матрица ковариации \ n% s'% cov_mat)
Ковариационная матрица
[[1,00671141 -0,11010327 0,87760486 0,82344326]
[-0,11010327 1,00671141 -0,42333835 -0,358937]
[0.87760486 -0,42333835 1,00671141 0,96921855]
[0,82344326 -0,358937 0,96921855 1,00671141]] Более подробный способ, приведенный выше, был просто использован для демонстрационных целей, эквивалентно, мы могли бы использовать функцию numpy cov:
print ('Ковариационная матрица NumPy: \ n% s'% np.cov (X_std.T)) Затем мы выполняем собственное разложение ковариационной матрицы:
cov_mat = np.cov (X_std.T)
eig_val, eig_vecs = np.linalg.eig (cov_mat)
print ('Собственные векторы \ n% s'% eig_vecs)
print ('\ nСобственные значения \ n% s'% eig_val)
Собственные векторы
[[0.52237162 -0,37231836 -0,72101681 0,26199559]
[-0,26335492 -0,92555649 0,24203288 -0,12413481]
[0,58125401 -0,02109478 0,14089226 -0,80115427]
[0,56561105 -0,06541577 0,6338014 0,52354627]]
Собственные значения
[2,93035378 0,92740362 0,14834223 0,02074601] Корреляционная матрица
В частности, в области «Финансы», корреляционная матрица обычно используется вместо ковариационной матрицы. Однако собственное разложение ковариационной матрицы (если входные данные были стандартизированы) дает те же результаты, что и собственное разложение корреляционной матрицы, поскольку корреляционная матрица может пониматься как нормализованная ковариационная матрица.
Собственное разложение стандартизованных данных на основе корреляционной матрицы:
cor_mat1 = np.corrcoef (X_std.T)
eig_val, eig_vecs = np.linalg.eig (cor_mat1)
Print ('Собственные векторы \ n% s'% eig_vecs)
print ('\ nСобственные значения \ n% s'% eig_val)
Собственные векторы
[[0,52237162 -0,37231836 -0,72101681 0,26199559]
[-0,26335492 -0,92555649 0,24203288 -0,12413481]
[0,58125401 -0,02109478 0,14089226 -0,80115427]
[0,56561105 -0,06541577 0,6338014 0,52354627]]
Собственные значения
[2.808 0,92122093 0,14735328 0,02060771] Собственное разложение исходных данных на основе корреляционной матрицы:
cor_mat2 = np.corrcoef (X.T)
eig_val, eig_vecs = np.linalg.eig (cor_mat2)
print ('Собственные векторы \ n% s'% eig_vecs)
print ('\ nСобственные значения \ n% s'% eig_val)
Собственные векторы
[[0,52237162 -0,37231836 -0,72101681 0,26199559]
[-0,26335492 -0,92555649 0,24203288 -0,12413481]
[0,58125401 -0,02109478 0,14089226 -0,80115427]
[0,56561105 -0,06541577 0.6338014 0,52354627]]
Собственные значения
[2,808 0,92122093 0,14735328 0,02060771] Мы можем ясно видеть, что все три подхода приводят к одним и тем же собственным векторам и парам собственных значений:
- Собственное разложение ковариационной матрицы после стандартизации данных.
- Собственное разложение корреляционной матрицы.
- Собственное разложение корреляционной матрицы после стандартизации данных.
2 — Выбор основных компонентов
Сортировка собственных пар
Типичная цель PCA — уменьшить размерность исходного пространства признаков за счет его проецирования на меньшее подпространство, где собственные векторы будут формировать оси.Однако собственные векторы определяют только направления новой оси, поскольку все они имеют одинаковую единицу длины 1, что может быть подтверждено следующими двумя строками кода:
для ev в eig_vecs:
np.testing.assert_array_almost_equal (1.0, np.linalg.norm (ev))
print ('Все в порядке!') Все ок!
Чтобы решить, какой собственный вектор (ы) можно отбросить, не теряя слишком много информации для построения подпространства меньшей размерности нам необходимо проверить соответствующие собственные значения: собственные векторы с наименьшими собственными значениями несут наименьшее количество информации о распределении данных; это те, которые можно отбросить.
Обычный подход заключается в ранжировании собственных значений от наибольшего к наименьшему, чтобы выбрать верхние $ k $ собственных векторов.
# Составить список кортежей (собственное значение, собственный вектор)
eig_pairs = [(np.abs (eig_val [i]), eig_vecs [:, i]) для i в диапазоне (len (eig_val))]
# Сортировать кортежи (собственное значение, собственный вектор) от большего к меньшему
eig_pairs.sort (ключ = лямбда x: x [0], обратный = True)
# Визуально подтверждаем, что список правильно отсортирован, уменьшая собственные значения
print ('Собственные значения в порядке убывания:')
для i в eig_pairs:
print (i [0]) Собственные значения в порядке убывания:
- 2.808375
- 0,921220930707
- 0,147353278305
- 0,0206077072356
Объясненное отклонение
После сортировки собственных пар возникает следующий вопрос: «Сколько главных компонентов мы собираемся выбрать для нашего нового подпространства функций?» Полезной мерой является так называемая «объясненная дисперсия», которую можно вычислить по собственным значениям. Объясненная дисперсия говорит нам, сколько информации (дисперсии) можно отнести к каждому из основных компонентов.
tot = сумма (eig_val)
var_exp = [(i / tot) * 100 для i в отсортированном (eig_val, reverse = True)]
cum_var_exp = np.cumsum (var_exp) , затем
с plt.style.context ('seaborn-whitegrid'):
plt.figure (figsize = (6, 4))
plt.bar (диапазон (4), var_exp, alpha = 0.5, align = 'center',
label = 'индивидуальное объясненное отклонение')
plt.step (диапазон (4), cum_var_exp, где = 'mid',
label = 'кумулятивная объясненная дисперсия')
plt.ylabel ('Коэффициент объясненной дисперсии')
plt.xlabel ('Основные компоненты')
plt.legend (loc = 'лучший')
plt.tight_layout ()
plt.savefig ('PREDI2.png', format = 'png', dpi = 1200)
plt.show () График выше ясно показывает, что большая часть дисперсии (72,77% дисперсии, если быть точным) может быть объяснена только первым главным компонентом. Второй главный компонент все еще несет некоторую информацию (23,03%), в то время как третий и четвертый основные компоненты можно безопасно отбросить, не теряя слишком много информации.Вместе первые два основных компонента содержат 95,8% информации.
Матрица проекции
Пришло время перейти к действительно интересной части: построению матрицы проекции, которая будет использоваться для преобразования данных Iris в новое подпространство функций. Несмотря на то, что в названии «матрица проекции» есть приятное звучание, в основном это просто матрица наших сцепленных верхних собственных векторов k .
Здесь мы сокращаем 4-мерное пространство признаков до 2-мерного подпространства признаков, выбирая «два верхних» собственных вектора с наивысшими собственными значениями для построения нашей $ d \ times k $ -мерной матрицы собственных векторов $ \ mathbf {W } $.
matrix_w = np.hstack ((eig_pairs [0] [1] .reshape (4,1),
eig_pairs [1] [1] .reshape (4,1)))
print ('Матрица W: \ n', matrix_w) Матрица W:
[[0,52237162 -0,37231836]
[-0,26335492 -0,92555649]
[0,58125401 -0,02109478]
[0,56561105 -0,06541577]] 3 — Проекция в пространство новых функций
На этом последнем шаге мы будем использовать $ 4 \ times 2 $ -мерную матрицу проекции $ \ mathbf {W} $ для преобразования наших выборок в новое подпространство с помощью уравнения
$ \ mathbf {Y} = \ mathbf {X} \ times \ mathbf {W} $, где $ \ mathbf {Y} $ — это матрица размером $ 150 \ times 2 $ наших преобразованных выборок.
Y = X_std.dot (матрица_w)
с plt.style.context ('seaborn-whitegrid'):
plt.figure (figsize = (6, 4))
для лаборатории, col in zip (('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('синий', 'красный', 'зеленый')):
plt.scatter (Y [y == lab, 0],
Д [y == lab, 1],
label = lab,
c = col)
plt.xlabel ('Основной компонент 1')
plt.ylabel ("Основной компонент 2")
plt.legend (loc = 'нижний центр')
plt.tight_layout ()
plt.show () , тогда мы получаем следующий график
На этом графике мы идентифицировали каждый вид разным цветом для облегчения наблюдения. Здесь мы можем увидеть, как метод разделяет разные виды цветов и как использование PCA позволяет идентифицировать структуру данных.
В образовательных целях и для того, чтобы показать пошагово всю процедуру, мы прошли долгий путь, чтобы применить PCA к набору данных Iris. Однако, к счастью, уже существует реализация, в которой с помощью нескольких строк кода мы можем реализовать ту же процедуру, используя scikit-learn, который представляет собой простые и эффективные инструменты для интеллектуального анализа данных и анализа данных.
из sklearn.decomposition импортировать PCA как sklearnPCA
sklearn_pca = sklearnPCA (n_components = 2)
Y_sklearn = sklearn_pca.fit_transform (X_std)
с plt.style.context ('seaborn-whitegrid'):
plt.figure (figsize = (8, 6))
для лаборатории, col in zip (('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('синий', 'красный', 'зеленый')):
plt.scatter (Y_sklearn [y == lab, 0],
Y_sklearn [y == lab, 1],
label = lab,
c = col)
plt.xlabel ('Основной компонент 1')
plt.ylabel ("Основной компонент 2")
plt.legend (loc = 'нижний центр')
plt.tight_layout ()
plt.savefig ('PREDI3.png', format = 'png', dpi = 1200)
plt.show () Еще один пример
Наконец, чтобы проиллюстрировать использование PCA, мы приводим еще один пример. В этом случае мы показываем результаты, но не предлагаем детали расчетов, так как этапы расчета были подробно объяснены в предыдущем примере.Цель этого примера — зафиксировать концепции метода PCA.
Предположим, что у нас есть средняя оценка, которую 1000 респондентов сделали для семи марок автомобилей по трем характеристикам. Для простоты мы рассмотрим несколько переменных (только три), чтобы зафиксировать некоторые концепции; однако в реальном исследовании мы можем рассмотреть десять или двадцать характеристик, поскольку PCA имеет преимущества, когда размер анализируемого набора данных очень велик.
В следующей таблице показаны средние значения, которые респонденты присвоили каждому из брендов по трем рассматриваемым характеристикам:
После применения процедуры PCA к набору данных мы получаем это представление в новом пространстве (Comp1, Comp.2):
Основной результат отражен на графике баллов на приведенном выше рисунке, где мы представили наблюдения или бренды на осях, образованных первыми двумя основными компонентами (Comp.1 и Comp.2). Облако отдельных точек центрировано в начале координат, чтобы облегчить анализ данных. Все точки переменных могут быть расположены на одной стороне Comp1., Как в этом случае, то есть Comp.1> 0. Это происходит потому, что характеристики рассматриваемых переменных положительно коррелированы, и когда индивидуум (бренды) получает высокую Значения одной характеристики высоки и у других.
Помните, что главные компоненты — это искусственные переменные, которые были получены как линейные комбинации из характеристик, рассмотренных в исследовании, так что каждый бренд (отдельные лица) принимает значение в этом новом пространстве, которое состоит из проекции исходных переменных.
Чтобы интерпретировать результаты, мы можем провести следующий анализ:
В первом квадранте (см. Метку I на рисунке выше) мы отмечаем, что все значения Comp.1 принимают только положительные значения.Таким образом, Комп.1 квадранта I отличается элегантностью и комфортом, тогда как Комп. 2 отличается высокой мощностью. Тогда марка F, расположенная в этом квадранте II, имеет три изученных характеристики, и в этом смысле она будет лучшей маркой (обратите внимание на направление стрелок).
В четвертом квадранте (IV) значения Comp.1 больше 0; следовательно, размещенный на нем бренд (E) характеризуется элегантностью и комфортом, но не мощностью, поскольку в этом квадранте все значения Comp.2 принимают отрицательные значения.
В третьем квадранте (III) находятся как C, так и D, которые похожи, но не характеризуются ни одной из этих переменных. Поскольку они принимают очень низкие значения по всем рассматриваемым характеристикам, они являются худшими брендами.
Во втором квадранте (II) марка A характеризуется высокой мощностью, но не элегантностью или комфортом. Это связано с тем, что проекция A на Comp.2> 0, а его проекция на Comp1 <0.
Наконец, после анализа PCA мы можем сделать вывод, что лучшая автомобильная марка — F, вторая лучшая автомобильная марка — E, а третья лучшая марка — A.Остальные бренды — худшие, по мнению респондентов.
Резюме:
В этой статье мы представили краткое введение в методы матричной факторизации для уменьшения размерности многомерных наборов данных. В частности, мы описали основные этапы и основные концепции анализа данных с помощью анализа главных компонентов (PCA). Мы показали универсальность метода PCA на двух примерах из разных контекстов и описали, как можно интерпретировать результаты применения этого метода.
В APSL мы рассматриваем анализ данных как фундаментальную часть бизнеса. Работая над одними и теми же проектами, дизайнеры, программисты, специалисты по обработке данных и разработчики понимают, что каждый проект рассматривается как единое целое, а не как отдельные части. Аналитик данных получает все данные в соответствующем формате, а системы, участвующие в этих задачах, настроены на поглощение нагрузки в записи всей информации.
Если вам нужна дополнительная информация о том, что мы делаем или о наших знаниях в области обработки данных и о том, как мы можем помочь в ваших проектах, не стесняйтесь обращаться к нам.
Номер ссылки
Jolliffe I.T. Анализ главных компонентов. Нью-Йорк: Спрингер; 2002.
Джексон Дж. Э. Руководство пользователя по основным компонентам. Нью-Йорк: John Wiley & Sons; 1991.
Сапорта Г., Нианг Н. Анализ главных компонентов: приложение для статистического управления процессами. В: Govaert G, ed. Анализ данных. Лондон: John Wiley & Sons; 2009, 1–23.
Abdi. Х. и Уильямс Л.Дж. (2010). «Анализ главных компонентов». Междисциплинарные обзоры Wiley: вычислительная статистика. 2 (4): 433–459. DOI: 10.1002 / wics.101.
Шоу П.Дж.А. (2003) Многомерная статистика для наук об окружающей среде, Ходдер-Арнольд. ISBN 0-340-80763-6.
% PDF-1.5 % 1 0 объект > эндобдж 2 0 obj > поток конечный поток эндобдж 3 0 obj > / XObject> / ProcSet [/ PDF / Text / ImageC] / ColorSpace> / Font> / Properties >>> / MediaBox [0 0 595 808] / StructParents 1 / Rotate 0 >> эндобдж 5 0 obj > поток HWks۸_oKv »
.